HOW TO INFECT YOUR ORGANIZATION WITH HUMANE OPS Matty Stratton DevOps Advocate, PagerDuty @mattstratton
Slide 1

Slide 2

@mattstratton
Slide 3

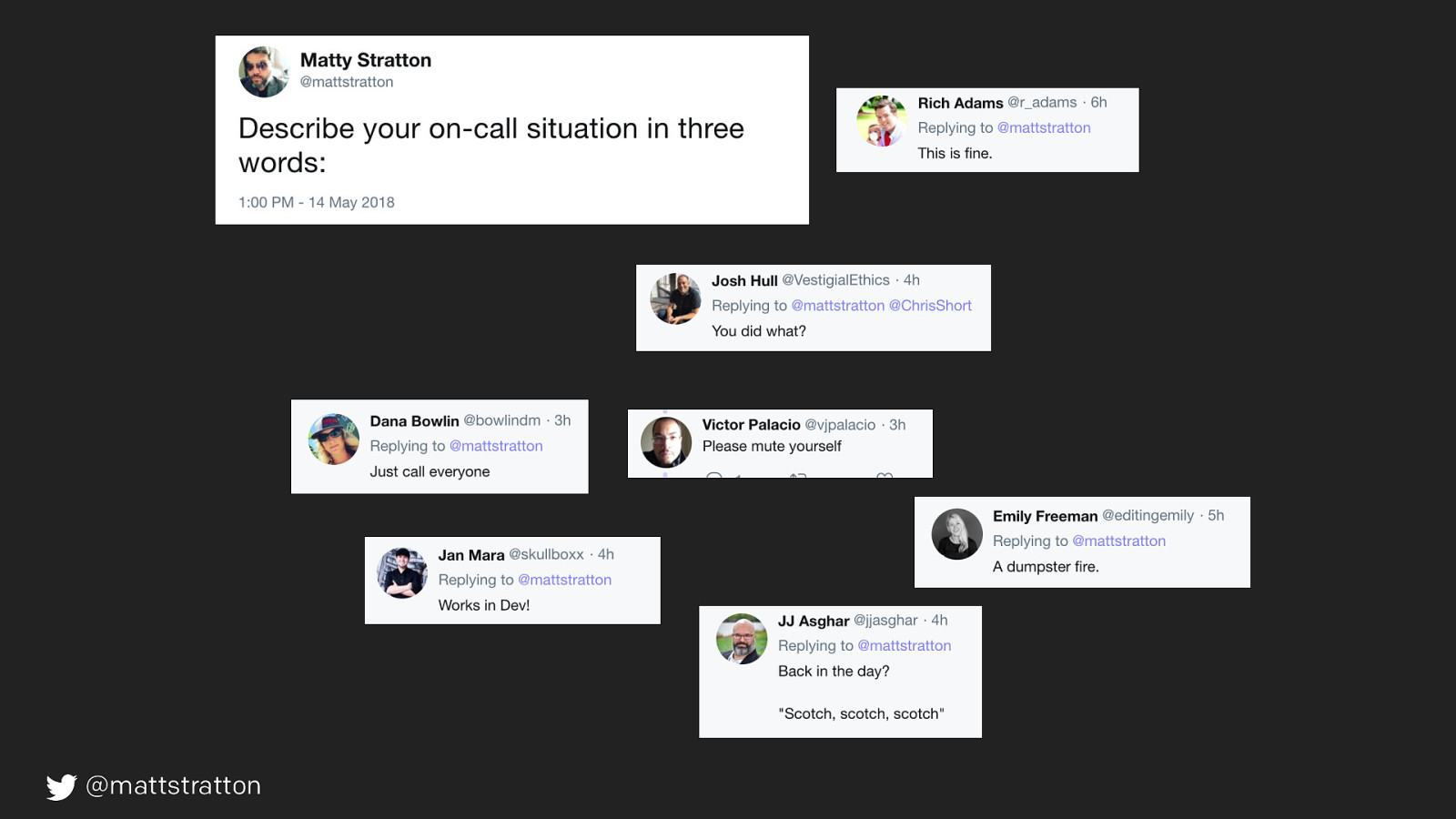
🔥📟 @mattstratton Who here has been on one of those phone calls where you are trying to troubleshoot an issue when something’s going wrong, and you’re trying to problem-solve with fellow human beings? Who here really enjoyed that experience and wants to do it all the time?
Slide 4
@mattstratton
Slide 5

THE DATA 50,000 RESPONDERS RECEIVING A TOTAL OF 760 MILLION NOTIFICATIONS ▸ 60 million notifications during dinner hours ▸ 82 million notifications during evening hours ▸ 250 million notifications during sleeping hours ▸ 122 million notifications on weekends ▸ A total of 750,000 nights with sleep-interrupting notifications ▸ A total of 330,000 weekend days with interrupt notifications @mattstratton PagerDuty commissioned a study across over 10,000 companies over 100 different segments.
Slide 6

LET’S HAVE SOME DATA THE MOST MEANINGFUL METRICS ON ATTRITION ARE ▸ Number of days where a responder’s work and life are interrupted ▸ Number of days when a responder is woken overnight ▸ Number of weekend days interrupted by notifications. @mattstratton
Slide 7

EXAMPLES OF MEMES ARE TUNES, IDEAS, CATCH-PHRASES, CLOTHES FASHIONS, WAYS OF MAKING POTS OR OF BUILDING ARCHES. JUST AS GENES PROPAGATE THEMSELVES IN THE GENE POOL BY LEAPING FROM BODY TO BODY, SO MEMES PROPAGATE THEMSELVES IN THE MEME POOL BY LEAPING FROM BRAIN TO BRAIN VIA IMITATION. @mattstratton Richard Dawkins @mattstratton
Slide 8
SNOW CRASH ▸ In the book, “Snow Crash” itself is a neurallinguistic virus. ▸ The bad guys figure out how to unlock it, and it spreads from hacker to hacker like a meme ▸ Plus, lots of swordplay “IDEOLOGY IS A VIRUS.” - NEAL STEPHENSON @mattstratton Remember, memes are another way of evolving across generations. This happens in the world of Snow Crash, but it can happen in your organization as well.
Slide 9
WHAT IF YOU ARE THE SUPREME LEADER? ▸ “Command and control” doesn’t work ▸ Use measurement for good, not for evil ▸ Avoid “executive swoop” @mattstratton
Slide 10
MIDDLE MANAGEMENT TIPS ▸ Encourage safe post-incident review spaces ▸ Drive for a culture of learning ▸ Take care of your people @mattstratton If people are up in the middle of the night, give them some comp time to recover. But this must be done within 24 hours, 48 at the max; it’s not a reward, it’s recovery time.
Slide 11

REVIEW. REVIEW. REVIEW A CULTURE OF LEARNING ▸ In a generative, performance-oriented organization, “failure leads to inquiry.” ▸ Don’t take my word for it. Ask Ron Westrum. ▸ You can also ask Dr. Nicole Forsgren - @nicolefv http://bit.ly/2KpzKKW @mattstratton If we don’t treat every outage or alert as something to learn from or something to improve, we run the risk of the Normalization of Deviance effect. In this case, we start to accept alerts or degradations as acceptable. Our standards suffer. We let things slip through the cracks.
Slide 12

USE THE FORCE, EVEN IF YOU AREN’T A JEDI @mattstratton
Slide 13

REVIEW ALL THE THINGS @mattstratton Andy Fleener, Platform Operations Manager, Sportsengine - “We review every alert from the last 24 hours/weekend every day. No broken windows.” Operational reviews are a thing - check out reviews.pagerduty.com for some guidance.
Slide 14

REVIEW. REVIEW. REVIEW NORMALIZATION OF DEVIANCE ▸ The gradual process through which unacceptable practice or standards become acceptable. As the deviant behavior is repeated without catastrophic results, it becomes the social norm for the organization. ▸ This happened to NASA. Twice. ▸ In our case, we start to accept alerts or degradations as acceptable. http://bit.ly/2Ihj1wV @mattstratton If we don’t treat every outage or alert as something to learn from or something to improve, we run the risk of the Normalization of Deviance effect. In this case, we start to accept alerts or degradations as acceptable. Our standards suffer. We let things slip through the cracks.
Slide 15

QUESTION METRICS @mattstratton Let’s make sure that we are setting the proper expectations. We don’t want to just expect five 9’s of reliability because “well, five is better than four.” Why do you need five? Have you tied your metrics to a business outcome? Likewise, your speed metrics shouldn’t be “faster than last month.” And beware of inaccurate extrapolation. You might have data suggesting that if your page load time increases by a second, conversion drops by 50 percent. But that doesn’t mean that if you reduce load time by a second, conversion will increase by 50 percent. Correlation doesn’t always equal causation, and the same numbers don’t move the dials in both directions.
Slide 16

QUESTION METRICS WHY ARE WE USING THESE NUMBERS? ▸ What is the data that drive your incident process ▸ Are your metrics tied to business outcomes? ▸ Correlation doesn’t always equal causation @mattstratton Let’s make sure that we are setting the proper expectations. We don’t want to just expect five 9’s of reliability because “well, five is better than four.” Why do you need five? Have you tied your metrics to a business outcome? Likewise, your speed metrics shouldn’t be “faster than last month.” And beware of inaccurate extrapolation. You might have data suggesting that if your page load time increases by a second, conversion drops by 50 percent. But that doesn’t mean that if you reduce load time by a second, conversion will increase by 50 percent. Correlation doesn’t always equal causation, and the same numbers don’t move the dials in both directions.
Slide 17
SIMPLE. ALWAYS. @mattstratton Don’t over-design systems. Resume-driven development is almost always a recipe for on-call disasters.
Slide 18

KEEP IT SIMPLE THE MORE RESILIENTLY THE SYSTEM IS DESIGNED, THE MORE LIKELY IT IS TO CAUSE A NEGATIVE BUSINESS IMPACT Stratton’s Law of Catastrophic Predestination @mattstratton At the heart of every complex resilient system is the hubris that someone believed they could predict everything that could go wrong. Fate, and the internet, laughs It’s not about how resilient the system IS…it’s about how resilient the attempted design.
Slide 19

COMMUNICATE. TALK TO PEOPLE ▸ Who are your customers? What are their expectations? ▸ Whose customer are you? Can you help them out? ▸ What are the perceptions of your team? @mattstratton ask how the on call is feeling during stand ups. give them the opportunity to mention they might be burning out.
Slide 20

HUMANS, PEOPLE ARE ▸ Consider contextual on-call ▸ The Golden Rule ▸ Bake cookies @mattstratton
Slide 21

LEARN TO TAKE COMMAND INCIDENT COMMAND @mattstratton volunteer to help as an incident commander (what’s that? Maybe we should have them!)
Slide 22

MAKE IT NICE ON THE BRIDGE DURING A CALL ▸ Have clearly defined roles ▸ Avoid bystander effect ▸ Rally fast, disband faster ▸ Don’t litigate severity ▸ Have a clear mechanism for making decisions @mattstratton You want to get all the right people on the call as soon as you need to…but you also want to get them OFF of the call as soon as possible.
Slide 23

SHARING IS CARING SHARE ALL TESTS @mattstratton
Slide 24

SHARE ALL TESTS TESTS ARE FOR SWE AND SRE BOTH ▸ All functional tests used in preproduction should have a corresponding monitor in production ▸ All monitoring functionality in production should have corresponding tests in the build/release process ▸ Monitoring is testing with at time dimension. There should be full parity between preproduction and production. @mattstratton
Slide 25

EVERY SPRINT DO ONE NICE THING @mattstratton
Slide 26

HELP YOUR RESPONDERS IN EACH AND EVERY SPRINT ▸ In each sprint/work unit, add value to your responders ▸ Even if it’s not on a card ▸ You rebel, you. @mattstratton Even if it’s not on a card
Slide 27
ADDING VALUE SOME EXAMPLES ▸ Provide better context in logging (stacktraces alone don’t count) ▸ Remove some technical debt. Yes, you have some. ▸ Add some (useful) tests ▸ Remove something unused @mattstratton These might seem obvious, but if they’re so obvious, I assume you’ve done them already?
Slide 28

ADDING VALUE ▸ If you use feature flags, add a description field to the configuration ▸ If you use runbooks, ensure they are up to date every time you cut a release. If you don’t do this, abandon the runbook altogether (an incorrect runbook is considered harmful) ▸ SIMPLIFY, MAN! @mattstratton
Slide 29

@MATTSTRATTON LINKEDIN.COM/IN/MATTSTRATTON MATTSTRATTON.COM ARRESTEDDEVOPS.COM SHARE YOUR ON-CALL STORIES WITH ME LATER @mattstratton
Slide 30

MATTSTRATTON.COM/SPEAKING @mattstratton
Slide 31

FURTHER READING AND REFERENCES ▸ Improving Your Employee Retention With Real-Time Ops Data - http://bit.ly/ 2rGTnq4 ▸ Page It Forward! - http://bit.ly/2In8Lzc ▸ The study of information flow: A personal journey - http://bit.ly/2KpzKKW ▸ The Normalization of Deviance (If It Can Happen to NASA, It Can Happen to You) - http://bit.ly/2Ihj1wV @mattstratton
Slide 32
▸ Snow Crash by Neal Stephenson - http://bit.ly/2Iiuc8L ▸ The Cybersecurity Canon: Snow Crash - http://bit.ly/2InDYGI ▸ Disasters! Arrested DevOps Episode 37 - https://arresteddevops.com/37 ▸ PagerDuty Incident Response - http://response.pagerduty.com @mattstratton