The Proactive Approach Data Driven Observability & Incident Response Matty Stratton & PJ Hagerty
Slide 1

Slide 2

About Matty PagerDuty.com PJ Hagerty | @aspleenic | Humio.com Matty Stratton | @mattstratton | PagerDuty.com
Slide 3
About PJ Humio.com Logging, Monitoring, Observability PJ Hagerty | @aspleenic | Humio.com Matty Stratton | @mattstratton | PagerDuty.com
Slide 4

PJ Hagerty | @aspleenic | Humio.com Matty Stratton | @mattstratton | PagerDuty.com You are about to see a bunch of animated gifs. It’s okay if you aren’t familiar with the subject, you may have never skipped school and that’s okay. We just wanted to let you know.
Slide 5
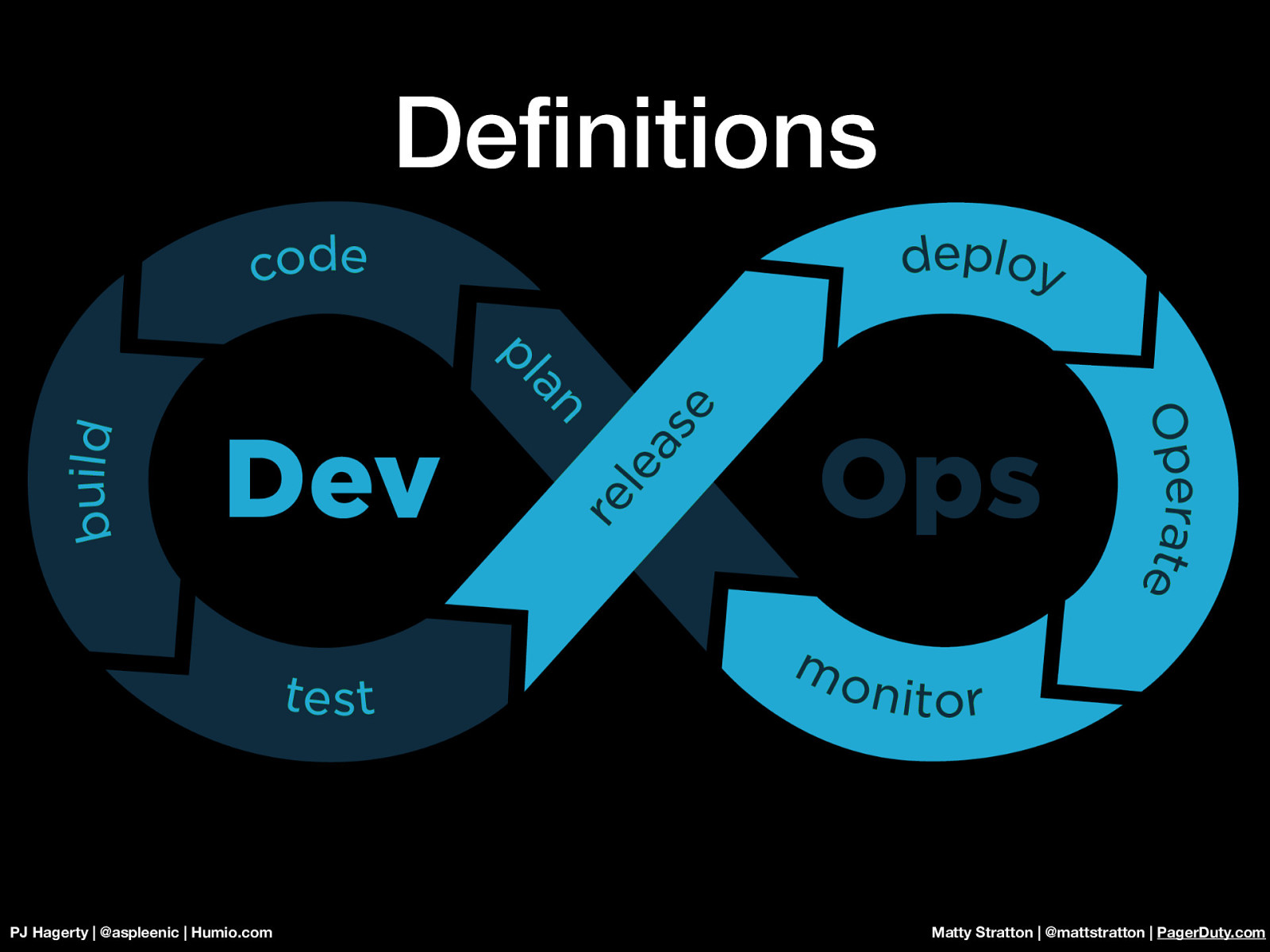
Definitions PJ Hagerty | @aspleenic | Humio.com Matty Stratton | @mattstratton | PagerDuty.com Before getting started there are a few things we need to define so we understand where it is we plan on going and how things as seemingly divorced from each other as Observability and Incident Response might actually be closely coupled. To do this we need to establish a language or agreed upon meeting point. For those of you new to some of these concepts, we will start with the umbrella term DevOps. This is a portmanteau of Development and Operations and it is squarely where most of what we are talking about will sit. Building from the Agile philosophy, DevOps is a concept of using tools, like Humio and PagerDuty, as catalysts for an optimal cycle of building, testing, and deploying applications. This is the overall concept and we need not get too deep into it, but for now, we know where we are looking to understand what we are doing.
Slide 6

Definitions PJ Hagerty | @aspleenic | Humio.com Matty Stratton | @mattstratton | PagerDuty.com Our next big term is observability. According to Rudolf Kalman who coined the phrase, observability is a measure of how well internal states of a system can be inferred from knowledge of its external outputs. Clearly, this definition was developed from an understanding of engineering complex machines where moving parts were internal and their dynamics could only be monitored via extrapolation. Unfortunately, that definition doesn’t apply for modern application development and the infrastructure monitoring necessary to keep the world moving forward in technology. Engineering has experienced a cultural shift that requires live observability and data driven monitoring. We will take a look at redefining this as we move forward
Slide 7

Definitions PJ Hagerty | @aspleenic | Humio.com Matty Stratton | @mattstratton | PagerDuty.com Another piece of this puzzle is the SRE or Site Reliability Engineer. This is the person, or team of people, responsible for taking all these observed behaviors and taking action. That could be solving a problem proactively, like buffing the infrastructure for a known event, or perhaps dealing with something reactively - like fighting a fire because code was released to production on Friday just before everyone left for the weekend and now things have gone wrong and it’s 3 AM and hey, there’s PagerDuty to let me know something is wrong.
Slide 8

Definitions PJ Hagerty | @aspleenic | Humio.com Matty Stratton | @mattstratton | PagerDuty.com I’m sure we are all familiar with the idea behind the Feedback Loop. It’s one of the most important concepts in DevOps - the ability to keep moving forward based on the feedback the process itself has informed us of. This is the way we understand what we need to do and is a MAJOR part of the proactive concept. We’ll look more into the tools on this later in the talk as we know what it is, so it needs a little less attention.
Slide 9

Feedback Loop PJ Hagerty | @aspleenic | Humio.com Matty Stratton | @mattstratton | PagerDuty.com We know the feedback loop is key to what we do. It informs us and allows us to make adjustments and learn from the behaviors of our users, past and present. This means we can work toward proactive development based on our reactive past. But feedback requires tools. Tools that humans can use. Let’s not let our modern star shine too brightly either. Humans have been building tools to make their tasks easier since long before now…actually, since long before humans. That, however is a talk for another time. Some of the modern tools people are using include monitoring, continuous integration and continuous delivery. QA tools continue to grow as well. Another piece of the puzzle is the concept of chaos engineering. If you’ve never heard of it, here’s a quick primer.
Slide 10

Feedback Loop PJ Hagerty | @aspleenic | Humio.com Matty Stratton | @mattstratton | PagerDuty.com Chaos engineering is the concept of testing systems, live, production systems, at times to see if they are resilient enough to sustain through the chaos. The concept was developed at Netflix and has spread to may organizations since, going so far as companies building chaos engineering as a service around the idea. What chaos engineering really provides is a way to get a glimpse at what’s happening when the worst occurs. Say half your production instances in AWS suddenly fail, or there is a DDOS attack and your site is hit. How well does your system perform? Does your application remain available to most users or is there a complete crash? Knowing how things will get handled, not only by the application but by your team of engineers, is key to understanding where the flaws and strengths in your application might be.
Slide 11

Feedback Loop PJ Hagerty | @aspleenic | Humio.com Matty Stratton | @mattstratton | PagerDuty.com The next key feature in the proactive programming feedback loop is observability. This is the direct feedback from your application, infrastructure, and all other systems that allows you to see how everything is functioning, from sandbox to testing to production. There was a time when folks would write code, no tests, no QA, and deploy directly into production. That time is past. We are better than that. Luckily here we have great tools, like Humio, that can see into the system from end to end in real time. But that’s not the only tool. Things like Travis CI and GoCD can let you know where the hiccups might be before they hit production. All of this helps complete the loop. But let’s look a little further into observability.
Slide 12

Observability PJ Hagerty | @aspleenic | Humio.com Matty Stratton | @mattstratton | PagerDuty.com Monitoring methods and tools are now more sophisticated and more widely adopted to handle increasingly distributed and complex systems. While it is now easier to observe code and tests and extrapolate that behavior, it’s also true all bets are off once your code hits the real world. So for the modern tech world, we’ve seen the need to redefine observability, as we mentioned earlier. For us, observability is the ability for teams to view information and investigate further how a given system is performing in real time, allowing for adjustments and fixes, in order to create better systems and identify threats in any complex computing environment.
Slide 13

Observability PJ Hagerty | @aspleenic | Humio.com Matty Stratton | @mattstratton | PagerDuty.com Real-time is critical when it comes to application development and monitoring. Most tools focus on digesting information and kicking it back after a certain period of time. This may not be ideal for many teams, especially those deploying multiple times per week, or even per day. Whether a sandbox environment or a production cluster, systems need to be monitored in concise intervals - near instantaneously. And we can’t see the full picture without making all aspects of what we are trying to observe readily available. Modern infrastructures generate large amounts of unstructured data but often only sample small parts, due to hardware constraints or high licensing fees. Slow query speeds and long latency between ingest-to-search makes that data not available “fast” enough for quick analysis. And complicated and complex solutions that are not easy to use, query, deploy or manage mean limited usage and pleasure in actually using them.
Slide 14

Observability PJ Hagerty | @aspleenic | Humio.com Matty Stratton | @mattstratton | PagerDuty.com This ultimately results in outdated observability for just parts of a system. Removing these obstacles empowers users and teams to quickly and easily query, analyze and visualize all of their data, instantly. Keeping things up to date removed some of the guess work in observing a system, whether it’s application logs or infrastructure information, you want it to be up to date. Data-driven observability means that you leverage all of your log data and use real-time streaming capabilities for querying and dashboards to power live system visibility for all engineers, not just Operations or Ops-minded DevOps folks
Slide 15

Observability PJ Hagerty | @aspleenic | Humio.com Matty Stratton | @mattstratton | PagerDuty.com Making systems better is the goal of observability teams. The more we know, the more we are able to improve and adjust. It’s commonly said software development is never “finished”. With this in mind, being able to observe and monitor what is happening out in the world allows our teams to build better, smarter, and get closer to the goals we keep pushing forward. We are eliminating some of the elements of surprise and making our application environment easier to manage.
Slide 16

Observability “[Observability is] not about logs, metrics, or traces, but about being data driven during debugging and using the feedback to iterate on and improve the product.” Cindy Sridharan - Distributed Systems Observability PJ Hagerty | @aspleenic | Humio.com Matty Stratton | @mattstratton | PagerDuty.com Remember not to get too caught up in tooling. Find a simple thing (not always the best or longest running - Humio is new and easy to use) that allows you to see into your systems and become proactive. Live system observability is about this data-driven, iterative process for teams that improves the overall health and resiliency of systems. And mitigating the issue of live system observability is at the top of the heap for every modern company or organization developing an application - be it web or mobile, fintech or funtech. Successful tools need to give developers, DevOps practitioners, security operations, systems administrators, and everyone else insight into how systems are functioning in real time. And they must be built to scale linearly and efficiently store data so users are not wasting their compute resources.
Slide 17
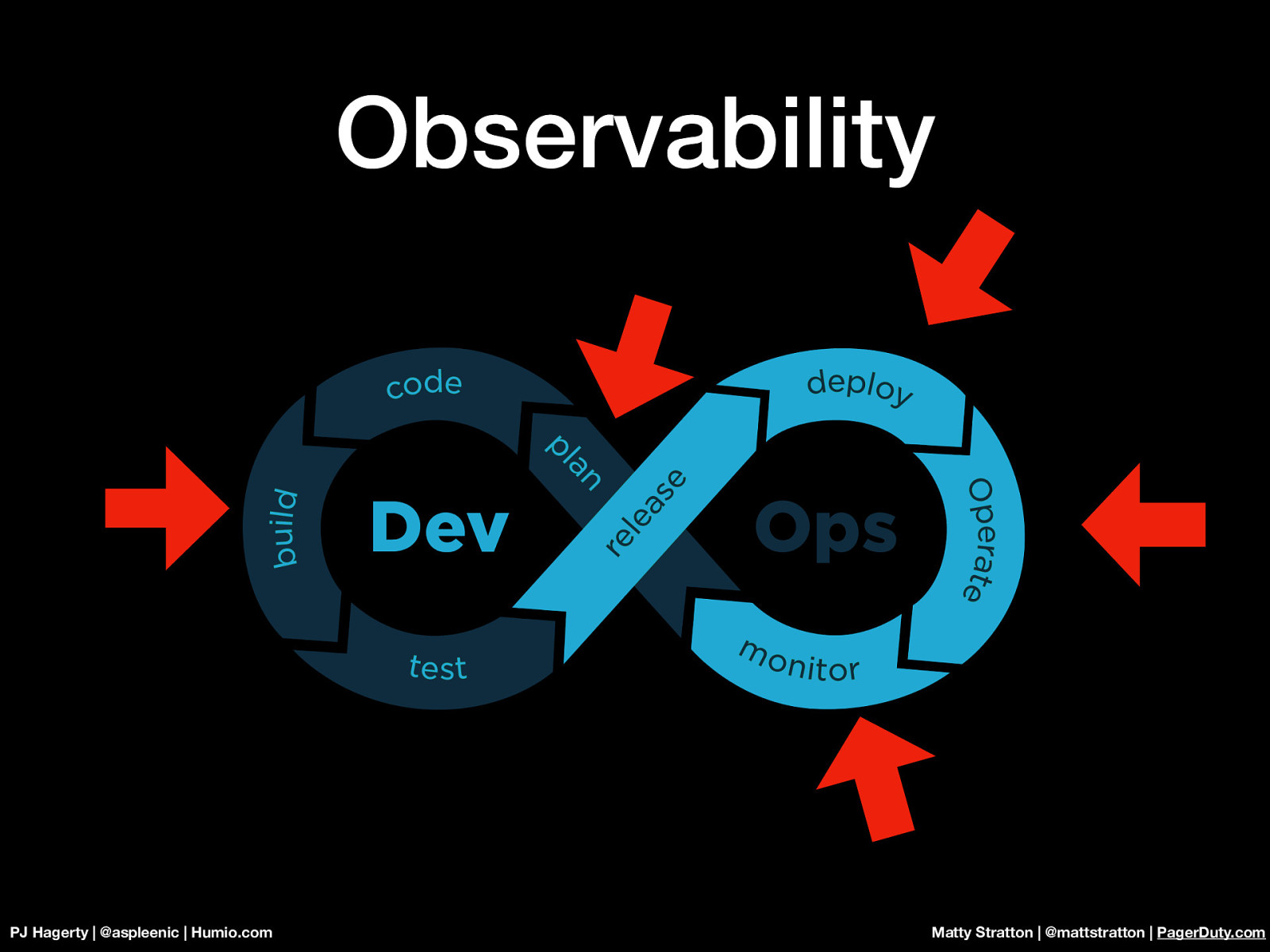
Observability PJ Hagerty | @aspleenic | Humio.com Matty Stratton | @mattstratton | PagerDuty.com From a tooling perspective, this requires handling large data volumes efficiently, and executing ingest and search with sub-second latency, in a simple solution. But observability is about more than just tools. It’s really about being several parts of that DevOps loop we talked about earlier - observability is part of building code, part of the operations and infrastructure monitoring plan, part of the overall application plan - it’s a major part of DevOps!
Slide 18

Proactive Programming Proactive programming focuses on eliminating problems before they have a chance to appear PJ Hagerty | @aspleenic | Humio.com Matty Stratton | @mattstratton | PagerDuty.com Proactive programming is relatively easy to define, if not so easy to execute. The idea is to eliminate problems before they become problems. Sounds simple right? No…not at all. What we are going to focus on in this talk is tools and techniques to make this process easier. That said, we are not talking about some weird psychic ability to determine what needs to be done before it happens. If anyone could do that, none of us would need jobs. The idea behind proactive programming is pushing the concept of isolating variables that might be easy to mitigate. We will take a look at some of these things as we move on, but for now, we know what the term means, and that’s a good start
Slide 19

Proactive Programming PJ Hagerty | @aspleenic | Humio.com Matty Stratton | @mattstratton | PagerDuty.com Again, I need to reiterate that Proactive Programming is not being an all-seeing, all-knowing mastermind. It’s nice if you can get the gig, but unlikely any human is qualified for it. Being proactive means that there is considerable work done first to establish a base for handling the user issues. The initial code doesn’t solve problems, rather it sets up the organization necessary to be able to do that in the future. This doesn’t mean you are giving up the flexibility and iterative nature of reactive programming completely. What it does mean is you will need to build a tool kit to plug holes and patch leaks before they happen.
Slide 20

Proactive Programming PJ Hagerty | @aspleenic | Humio.com Matty Stratton | @mattstratton | PagerDuty.com Think of proactive programming like building a house. You start with a strong, solid foundation. Regardless of what happens as things progress, the house will stand and be safe - because you’ve built it on something that can’t be shaken. In the case of reactive programming, our foundation might be flexible yet far from sturdy. Our idea is built, but it looks more like a pillow fort than a mansion. While it’s fun and it looks cool, it’s not going to be very helpful when the wind and rain come. Being Proactive means we are expecting the rain at some point. We may not know when, but we know it’s will happen. So we prepare - put in nice double paned windows and dependable roof tiles.
Slide 21

Proactive Programming PJ Hagerty | @aspleenic | Humio.com Matty Stratton | @mattstratton | PagerDuty.com In proactive development you solve matters before they become an issue. You generally spend more times on the optimizations (for example, improved security or caching of everything). Proactive development makes developments more stable, but you could anticipate the wrong future and end up spending lots of time on something that isn’t important. This where you hear terms like observability and chaos engineering tossed around. We will talk more about both those things in a bit, but for now, be aware there will need to be schema shift if you are moving from a reactive to a proactive situation. Just like when you abandoned Waterfall for Agile then went all DevOps.
Slide 22

Proactive Programming PJ Hagerty | @aspleenic | Humio.com Matty Stratton | @mattstratton | PagerDuty.com When it comes to proactive engineering, the focus is on being as safe and secure as you can possibly be before putting things out into the world. This means having a tight feedback loop. The key drawback to proactive development is it will take more time in the initial stages. Things can be fast and flexible or sturdy and secure. Pick one and decide what works best in your organization. Chances are security is top of the list, so proactive will be a bigger benefit.
Slide 23

All of it Together PJ Hagerty | @aspleenic | Humio.com Matty Stratton | @mattstratton | PagerDuty.com All of this: the feedback loop, observability, proactive programming - they are meant to make your team more resilient. The honest truth? Nothing will make you 100% bullet proof. So what happens when it all goes side ways? At this point, I’ll hand the mic over to Matty to go through how this ties into the world of Incident Response and what it means for your team.
Slide 24

What is incident response? PJ Hagerty | @aspleenic | Humio.com Matty Stratton | @mattstratton | PagerDuty.com
Slide 25

Any unplanned disruption or degradation of service that is actively affecting customers’ ability to use the product. PJ Hagerty | @aspleenic | Humio.com Matty Stratton | @mattstratton | PagerDuty.com
Slide 26
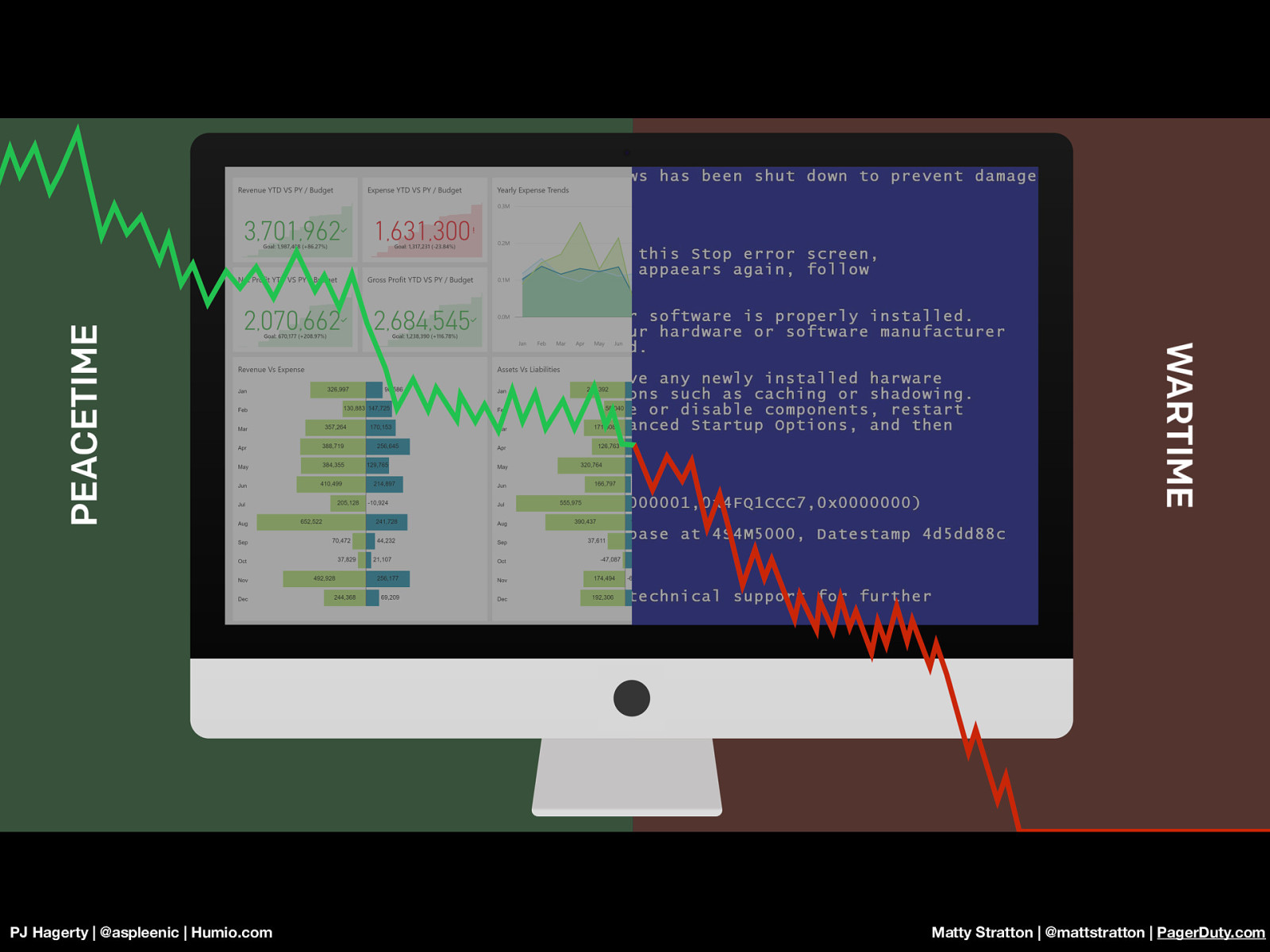
PJ Hagerty | @aspleenic | Humio.com Matty Stratton | @mattstratton | PagerDuty.com Once an incident is triggered, we need to switch our mode of thinking. We need a mentality shift. We want a distinction between “normal operations” and “there’s an incident in progress”. We need to switch decision making from peacetime to wartime. From day-today operations, to defending the business. Something that would be considered completely unacceptable during normal operations, such as deploying code without running any tests, might be perfectly acceptable during a major incident when you need to restore service quickly. The way you operate, your role hierarchy, and the level of risk you’re willing to take will all change as we make this shift. “Fire isn’t an emergency to the fire department. You expect a rapid response from a group of professionals, skilled in the art of solving whatever issues you are having.” [Quote from Blackrock 3] - http://www.blackrock3.com/blog/incident-management-meets-it-operations
Slide 27
PJ Hagerty | @aspleenic | Humio.com Matty Stratton | @mattstratton | PagerDuty.com Some people don’t like the peacetime/wartime analogy, so you can call it what you want. Normal/Emergency.
Slide 28
PJ Hagerty | @aspleenic | Humio.com Or OK/NOT OK. What you call it isn’t as important as being able to make the mental shift. Matty Stratton | @mattstratton | PagerDuty.com
Slide 29

Don’t litigate severity PJ Hagerty | @aspleenic | Humio.com Matty Stratton | @mattstratton | PagerDuty.com
Slide 30

Incident Commander PJ Hagerty | @aspleenic | Humio.com Matty Stratton | @mattstratton | PagerDuty.com
Slide 31

Not a resolver PJ Hagerty | @aspleenic | Humio.com Matty Stratton | @mattstratton | PagerDuty.com
Slide 32

Highest Ranking PJ Hagerty | @aspleenic | Humio.com Matty Stratton | @mattstratton | PagerDuty.com
Slide 33

Executive Swoop PJ Hagerty | @aspleenic | Humio.com Matty Stratton | @mattstratton | PagerDuty.com
Slide 34

Notify stakeholders PJ Hagerty | @aspleenic | Humio.com Matty Stratton | @mattstratton | PagerDuty.com
Slide 35

Sizing up PJ Hagerty | @aspleenic | Humio.com Matty Stratton | @mattstratton | PagerDuty.com
Slide 36

Making decisions PJ Hagerty | @aspleenic | Humio.com Is there any strong objection? Matty Stratton | @mattstratton | PagerDuty.com
Slide 37

This background is blue. Let’s look at a quick example to show what I mean. I propose that this background is blue. Does everyone agree? (Point to about 5 different people in the room one by one and ask if they agree). See how long it’s taking us to reach consensus? Distributed consensus is hard, you’ll be there forever trying to agree on the proposed actions. Let’s try it a different way though. I propose that this background is blue. Are there any strong objections? … Hearing none, background is blue, let’s proceed.
Slide 38

Rally fast, disband faster PJ Hagerty | @aspleenic | Humio.com Matty Stratton | @mattstratton | PagerDuty.com
Slide 39

Don’t panic PJ Hagerty | @aspleenic | Humio.com Matty Stratton | @mattstratton | PagerDuty.com
Slide 40

At the end of the call PJ Hagerty | @aspleenic | Humio.com Matty Stratton | @mattstratton | PagerDuty.com
Slide 41

Post-mortems PJ Hagerty | @aspleenic | Humio.com Matty Stratton | @mattstratton | PagerDuty.com
Slide 42

How do we do it? https://response.pagerduty.com PJ Hagerty | @aspleenic | Humio.com Matty Stratton | @mattstratton | PagerDuty.com
Slide 43

Questions? PJ Hagerty | @aspleenic | Humio.com Matty Stratton | @mattstratton | PagerDuty.com