The talk
How Do You Infect Your Organization With Humane Ops?
Delivered 9 times · 2018–2020



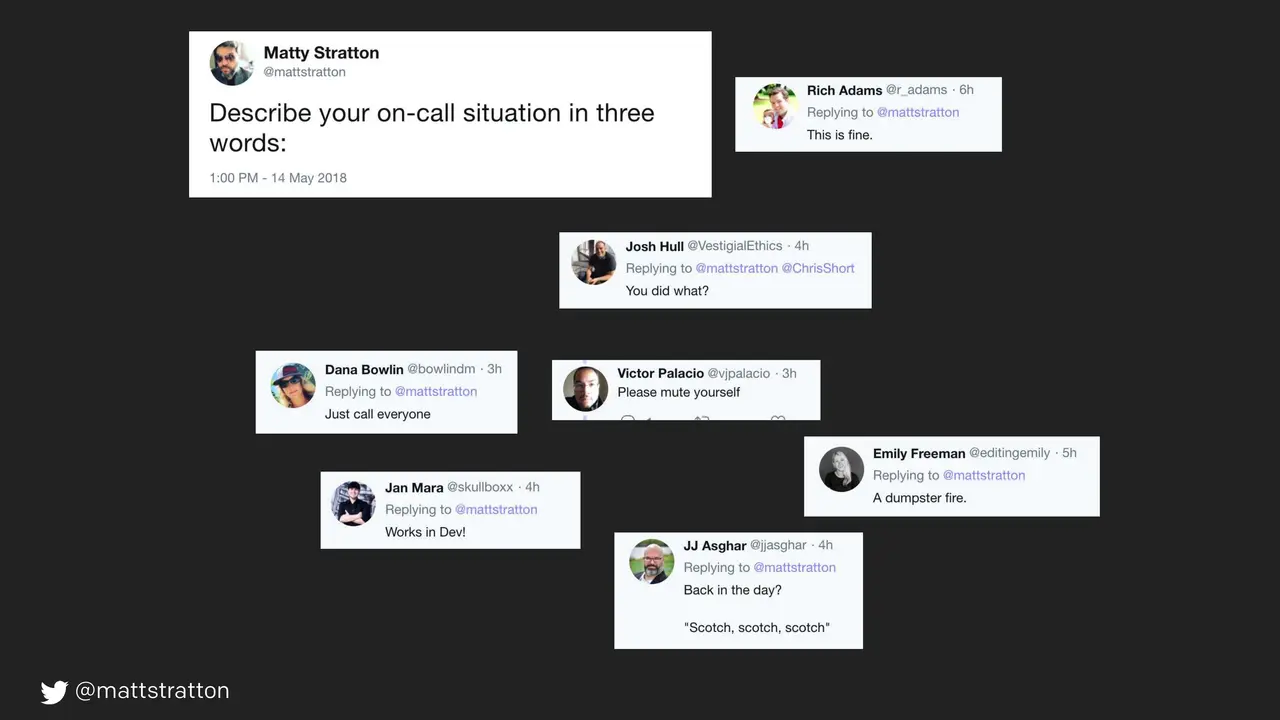


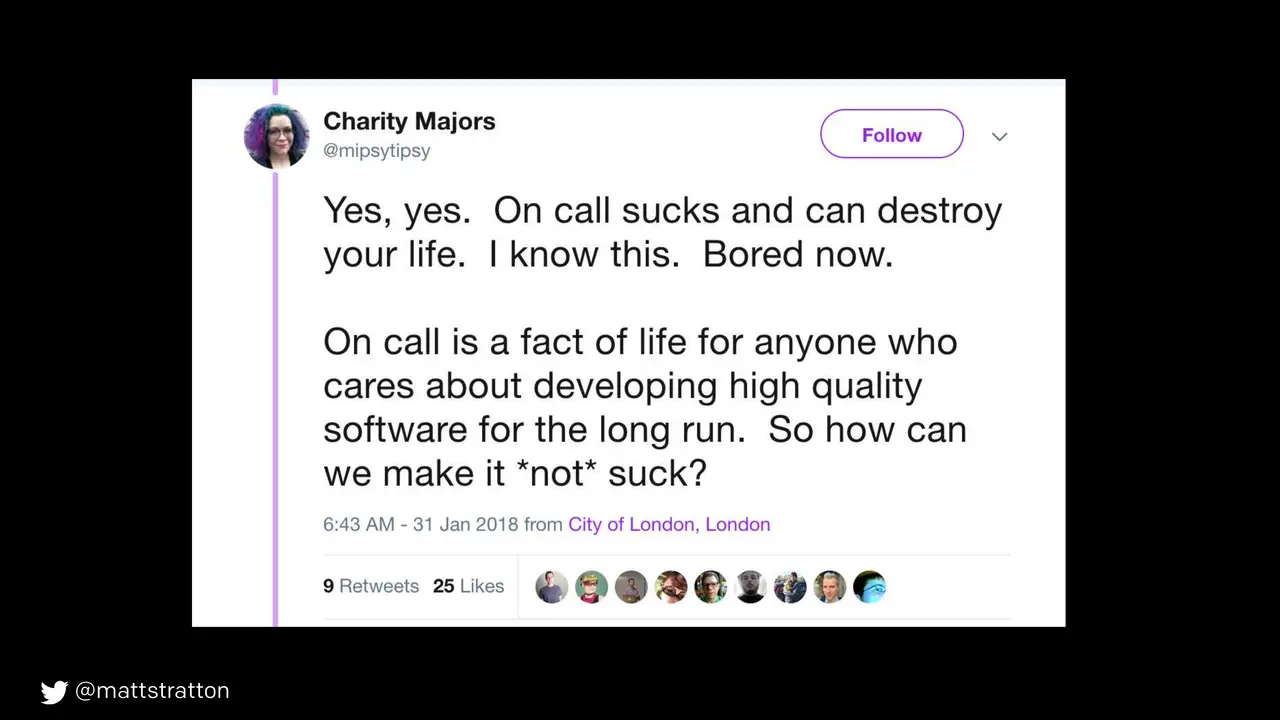










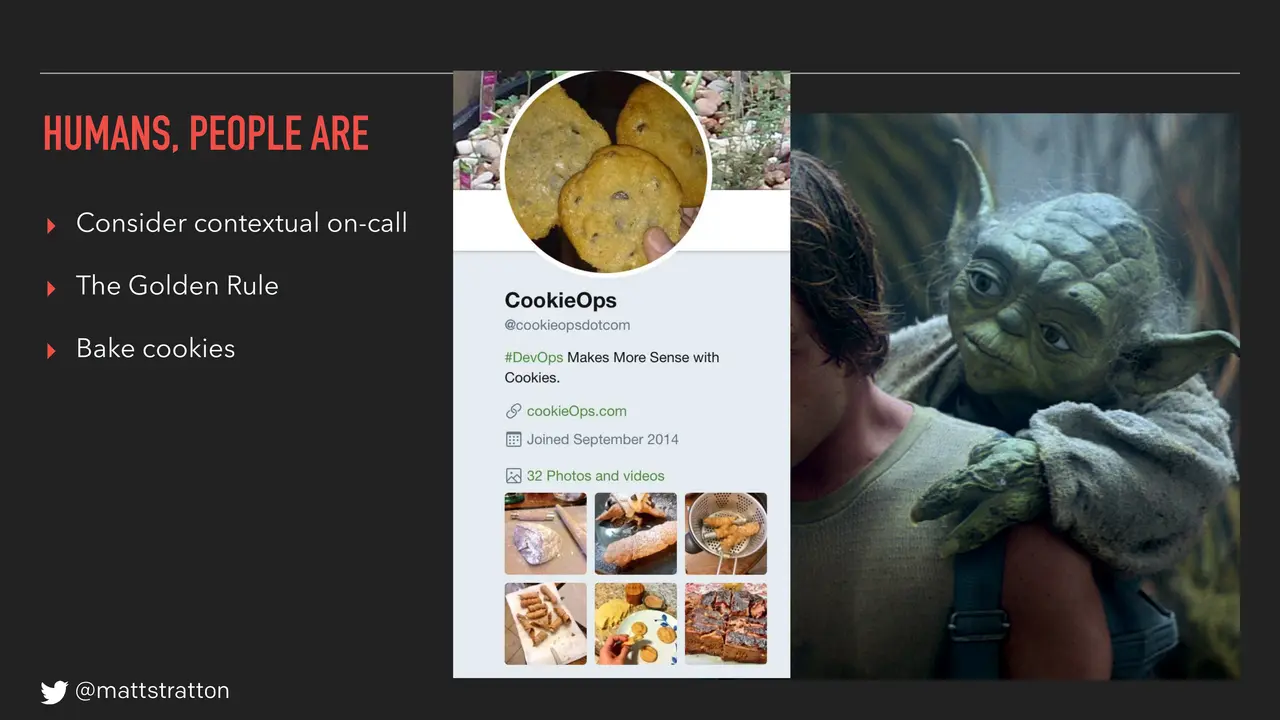










Richard Dawkins described memes as being a form of cultural propagation, which is a way for people to transmit social memories and cultural ideas to each other. Not unlike the way that DNA and life will spread from location to location, a meme idea will also travel from mind to mind.
Getting your organization to take a step back and look at how ops affects people (awareness of alert fatigue, burnout risk, proactive/reactive approaches) can be a tough challenge.
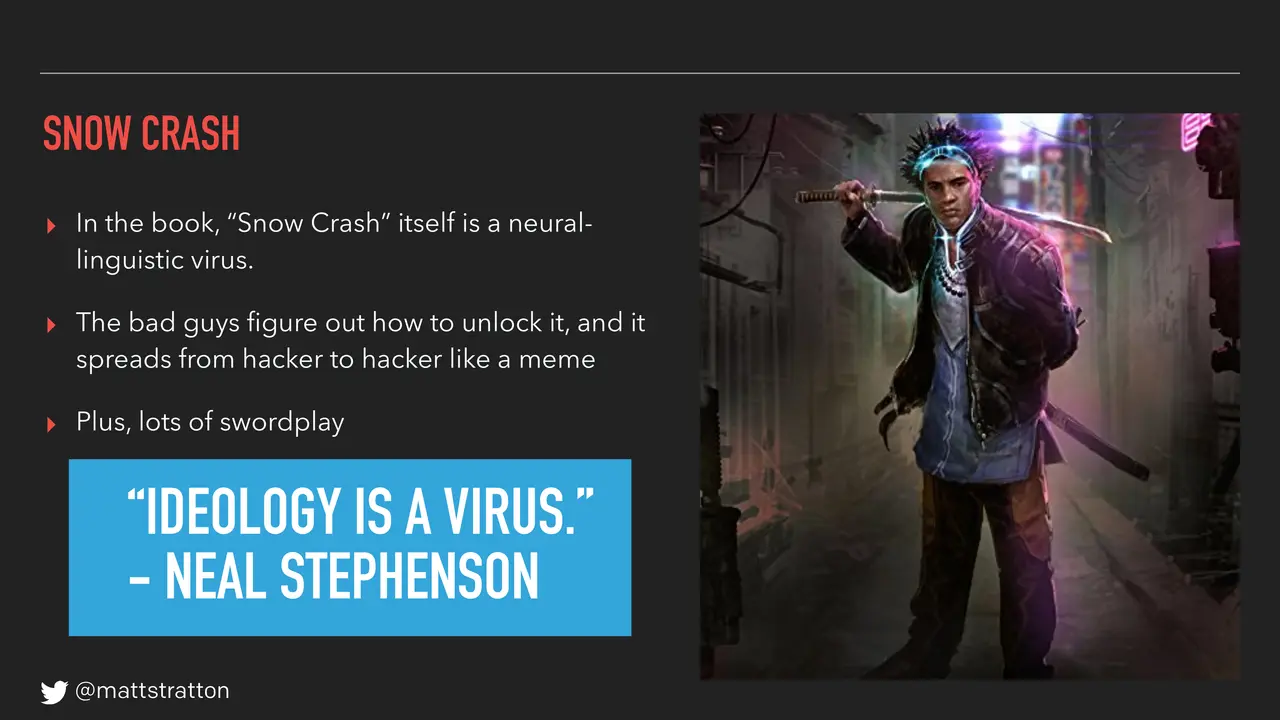
In this talk, I will discuss how the very DNA of an organization can evolve through the use of actionable communications from all levels - management, strategy, and practitioners. The “virus” of humane ops will infect your organization, providing a more sustainable approach to on-call, incident resolution, post-mortems, and more. There also will be copious references to the Neal Stephenson classic novel, Snow Crash.
After this talk, you will have ideas of practical approaches to effect change in your organization, regardless of your level of influence. While not every group will use the same “viruses”, you will take away a good understanding of where to get started as Patient Zero.
Every delivery (9)
- PagerDuty London Meetup Jan 2020 · London, UK slides
- 2019 NanoConf May 2019 · Redmond, WA, USA slides
- Microsoft TechDays 2019 - Finland Feb 2019 · Helsinki, Finland slides
- DevOpsDays Philadelphia Oct 2018 · Philadelphia, PA, USA slides
- DevOpsDays Kansas City 2018 Oct 2018 · Kansas City, MO, USA video slides
- PagerDuty Tour Amsterdam Oct 2018 · Amsterdam, Netherlands slides
- DevOpsDays Riga 2018 Sep 2018 · Riga, Latvia slides
- DevOpsDays Amsterdam 2018 Jun 2018 · Amsterdam, Netherlands video slides
- DevOpsDays Salt Lake City 2018 May 2018 · Salt Lake City, UT, USA slides
Resources
- Improving Your Employee Retention With Real-Time Ops Data
- Page It Forward!
- The study of information flow: A personal journey
- The Normalization of Deviance (If It Can Happen to NASA, It Can Happen to You)
- Snow Crash by Neal Stephenson
- The Cybersecurity Canon: Snow Crash
- PagerDuty Incident Response
- Operational Reviews
- Operational Reviews
- Page It Forward!
- Snow Crash by Neal Stephenson
- The Cybersecurity Canon: Snow Crash
- Disasters! Arrested DevOps Episode 37
- The study of information flow: A personal journey
- The Normalization of Deviance (If It Can Happen to NASA, It Can Happen to You)
- Improving Your Employee Retention With Real-Time Ops Data