The talk
The Psychology of Chaos Engineering
Delivered 3 times · 2019–2020






















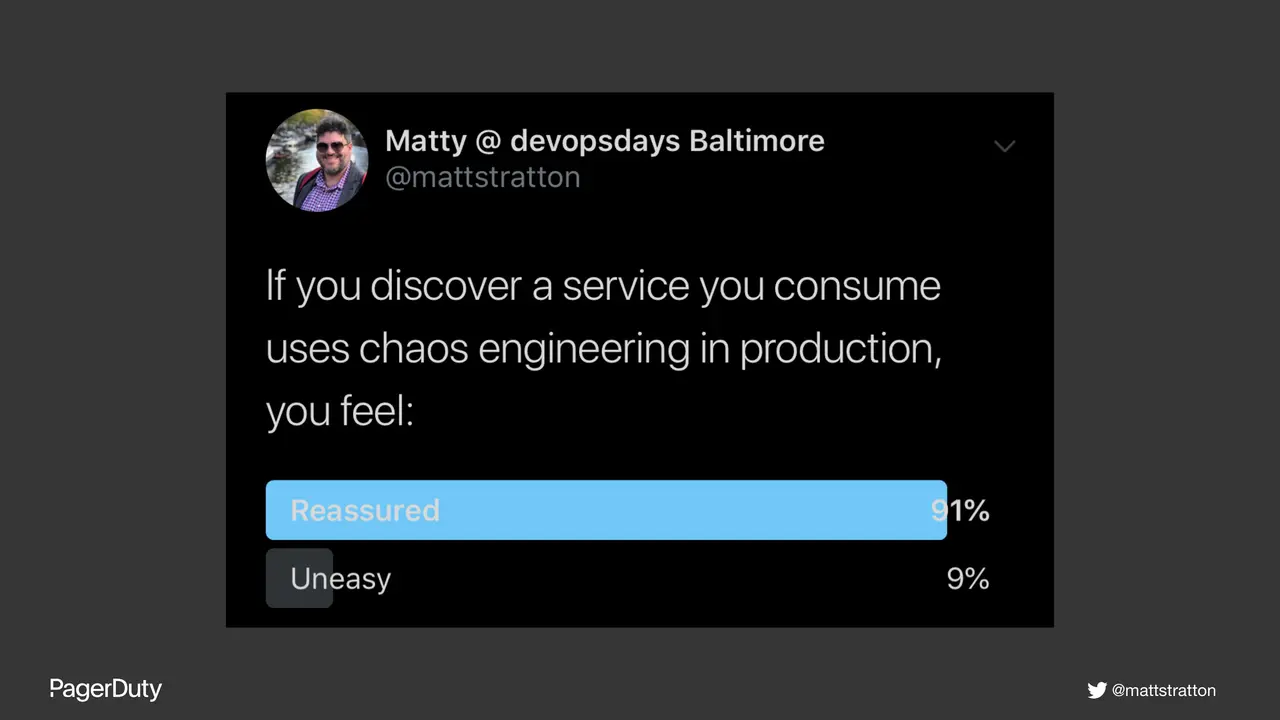

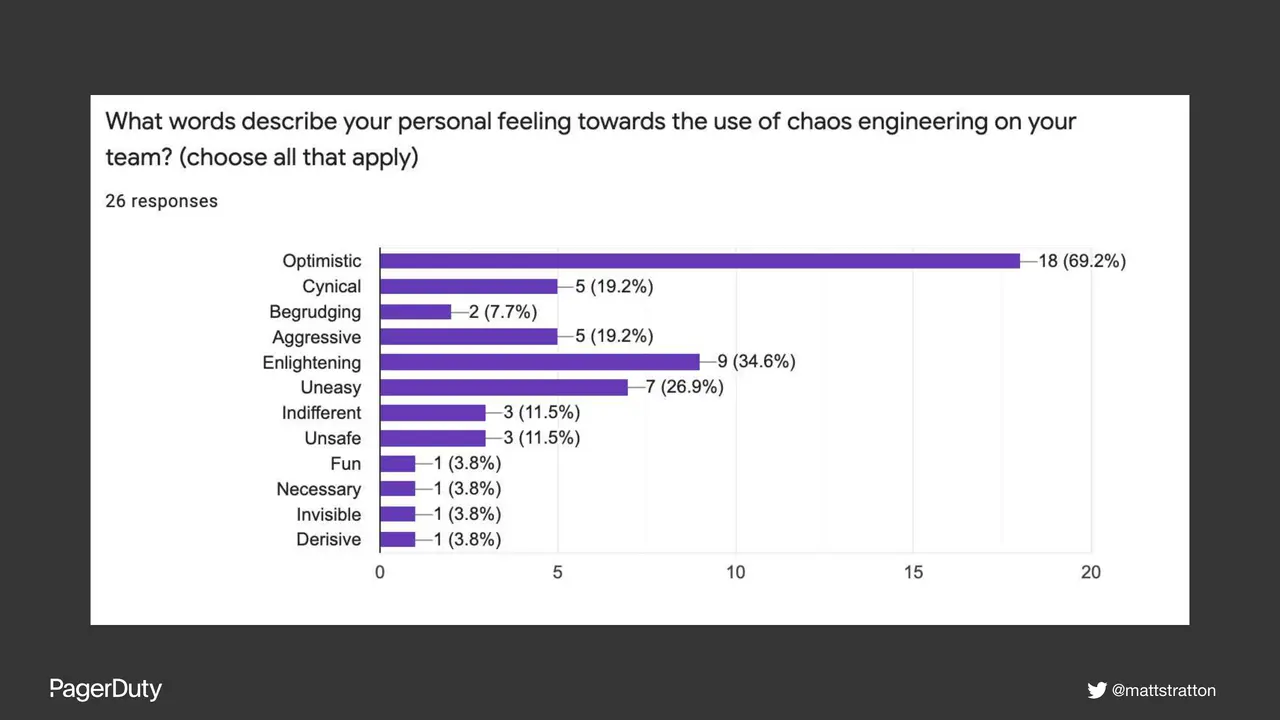
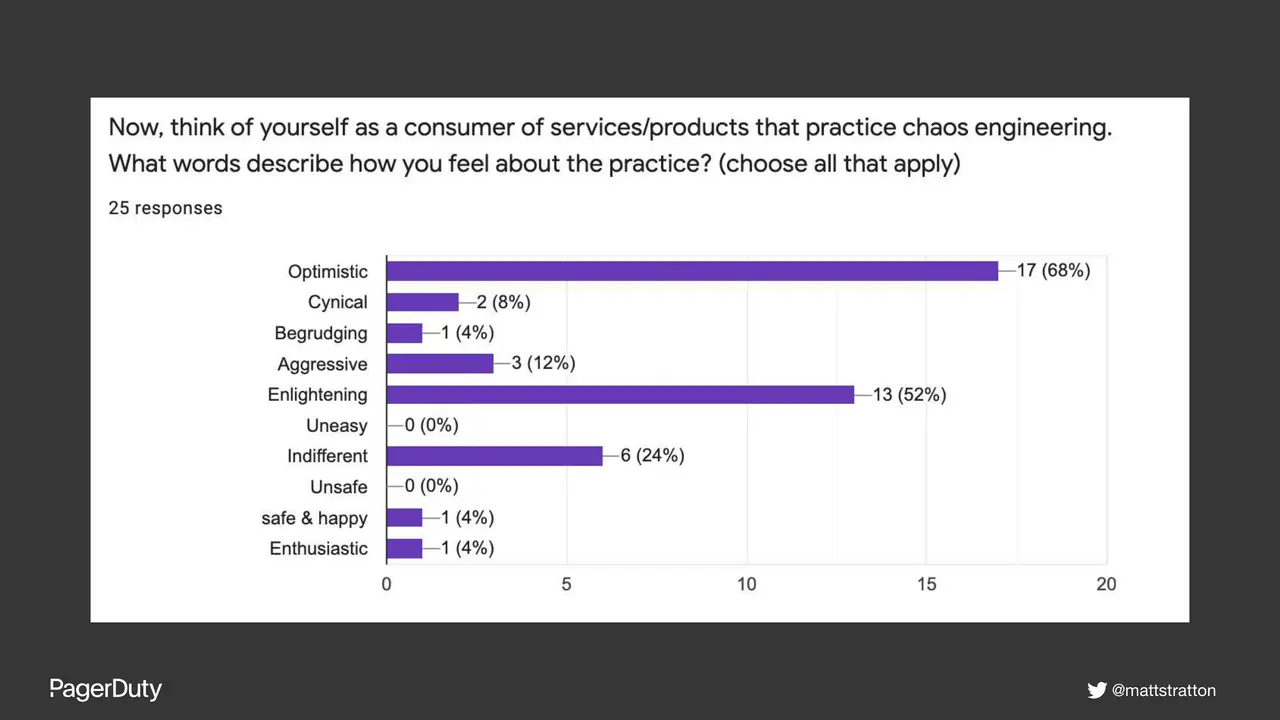



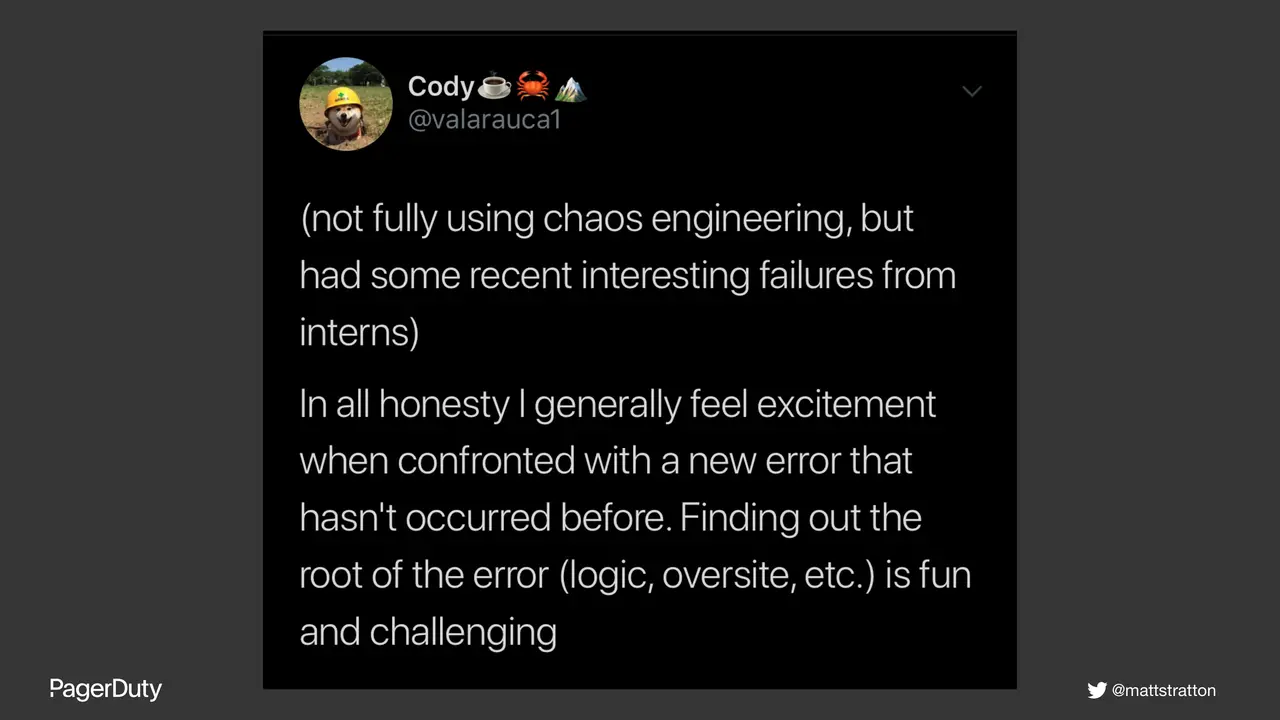




Chaos Engineering, failure injection, and similar practices have verified benefits to the resilience of systems and infrastructure. But can they provide similar resilience to teams and people? What are the effects and impacts on the humans involved in the systems? This talk will delve into both positive and negative outcomes to all the groups of people involved - including users, engineers, product, and business owners.
After seeing this talk, attendees will have a better understanding of the human factors involved in chaos engineering, good practices to care for the people and teams working with chaos, and be even more excited about this practice.
Observability & ResilienceThe Human Side