How Do You Infect Your Organization With Humane Ops?
DevOpsDays Amsterdam 2018 · · Amsterdam, Netherlands






















































Richard Dawkins described memes as being a form of cultural propagation, which is a way for people to transmit social memories and cultural ideas to each other. Not unlike the way that DNA and life will spread from location to location, a meme idea will also travel from mind to mind.
Getting your organization to take a step back and look at how ops affects people (awareness of alert fatigue, burnout risk, proactive/reactive approaches) can be a tough challenge.
In this talk, I will discuss how the very DNA of an organization can evolve through the use of actionable communications from all levels - management, strategy, and practitioners. The “virus” of humane ops will infect your organization, providing a more sustainable approach to on-call, incident resolution, post-mortems, and more. There also will be copious references to the Neal Stephenson classic novel, Snow Crash.
After this talk, you will have ideas of practical approaches to effect change in your organization, regardless of your level of influence. While not every group will use the same “viruses”, you will take away a good understanding of where to get started as Patient Zero.
Resources
Transcript · 6,179 words · ~31 min read
Lightly edited for readability from the video’s captions. Download as text
This talk is called "How to Infect Your Organization with Humane Ops." Humane Ops is a concept we talk about a lot — in fact this whole track is the Humane Ops track — so we're going to talk about those squirrely little things called people. My name is Matty Stratton. I'm a DevOps evangelist at PagerDuty.
This is usually the slide where I would put up my whole resume slide that talks about what I do and where I've been. I've kind of realized that nobody really cares. This is the part where normally in your presentation you're like, "This is why you should listen to me because I've done all these things." So instead I just have pictures of my kids to get you on my side, so you're like, well, these are just cute kids, right?
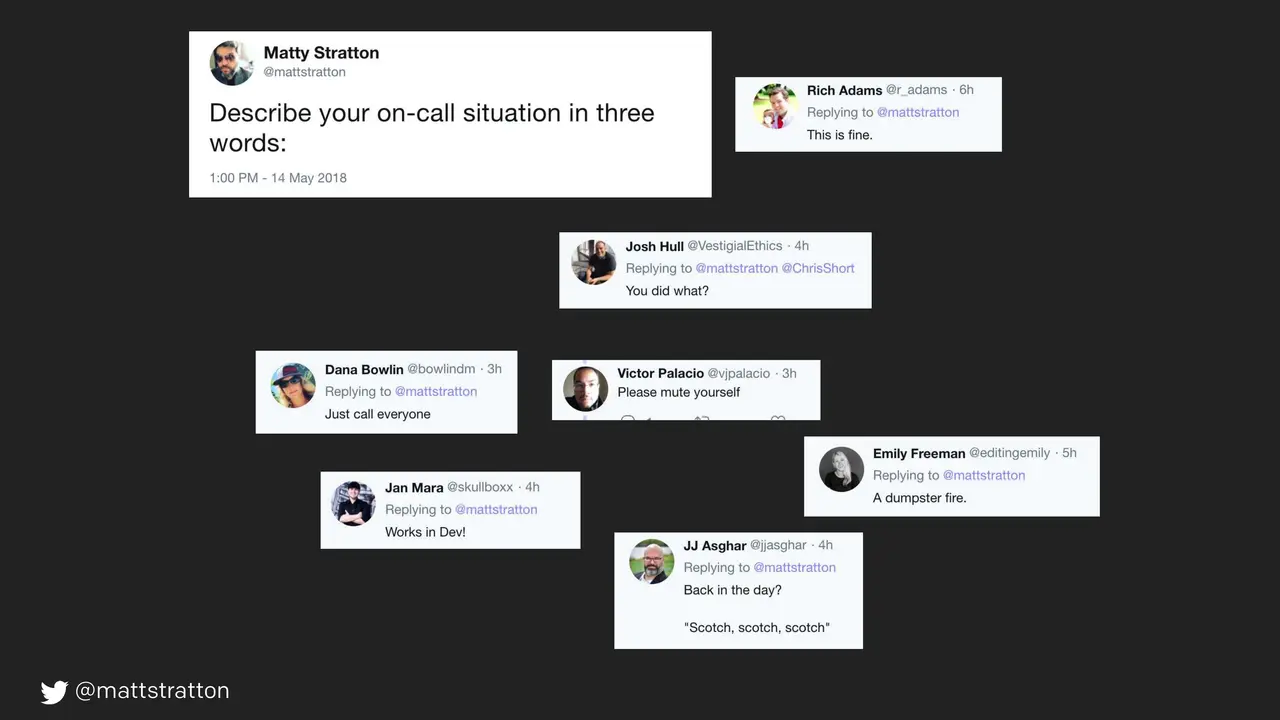
So usually when I'm trying to source ideas or content for talks I like to just go to Twitter and have other people do my work for me. So I went and I asked the question: describe your on-call situation in three words. And this was some of the responses that we got. I kind of liked "please meet yourself" and as Emily said, "a dumpster fire." So on-call is not delightful.
Yesterday Rachel talked a little bit about how we do on-call at PagerDuty and when you follow processes like good incident command it can make on-call more pleasant, or at least less unpleasant. But the reality is that nobody likes on-call, and in most environments and most teams and most organizations it's something we really don't like. What I want to talk about a little bit today is what are the things that we can do to make this a better experience for our colleagues.
I'm going to approach this from a couple of different ways, because a lot of times when we go out there and we say on-call should be better for our co-workers, everyone says, "Of course, that would be fantastic. Great. Well, what are you gonna do about it?" "Well, I can't do anything. I'm not a manager, I'm not a director, I'm not in the ELT. I don't have the ability to pay people to be on-call to make their life better. I can't do all these things that we mystically think only big important management-type people can do."
The reality is that there's something everybody can do to make on-call better, even if you're not part of the on-call rotation. Because maybe you disagree with me that devs should be on-call, maybe your organization doesn't have that be the case. You may be a software engineer that's not on-call — that doesn't mean that you don't have colleagues who have to deal with this, that you can do things to make better.
So I'm going to approach this from the perspective of someone who might be in management and the things you might be able to do, and also as individual contributors. Fundamentally, no matter what your role in the organization, there's something you can do to make it better.
But before that, let's talk a little bit about why. Why does this matter?
So we commissioned a study over 10,000 companies and over a hundred different industry segments, and this was a cause of 50,000 responders. During this time these were people who received over 760 million notifications, so it's a pretty big sample set. We wanted to understand what made people leave their job — people who were responders to incidents, why did they leave? These were all folks who had left their position in the last 18 months.
60 million notifications occurred during dinner hours, 82 million notifications occurred during evening hours, 250 million occurred during sleeping time, and 122 million over the weekend. These are all times when we're not supposed to be working — we're supposed to be having this mythical work-life balance. This is a total of almost three-quarters of a million nights that had sleep-interrupting notifications of some kind.
So what did we find? We discovered when we looked at those people who were responders to incidents and had left their position in the last 18 months, we found three most meaningful metrics on that attrition. One was the number of days where responders' work and life were interrupted. Number of days when a responder was woken overnight. And the number of weekend days. These are the three biggest things. When we did a survey across all these people it wasn't how much money do you make, it wasn't are your co-workers jerks — it was how many times do I get woken up in the middle of the night, how often is my work day interrupted by on-call, how often is my life interrupted.
Why do we care about attrition? Well, unfortunately using some US dollar numbers here because that's what I know, but in the US the average replacement cost of a software engineer or a technology engineer is three hundred and fifty thousand dollars. That's a lot of money, right, compared to being able to keep somebody. So it's pretty important. Besides the fact that we want to make on-call better, we want to make this experience better for our colleagues because they're fellow humans and we should treat fellow humans nicely — we also don't want to waste a lot of money.
So how do we go about doing this? This is Richard Dawkins, and Richard Dawkins coined the term "meme." We usually think about memes as the things that get put up on the screen, but a meme is also in general — as Dawkins said — tunes, ideas, catchphrases: things that propagate themselves into our gene pool by leaping from body to body. Memes propagate themselves from brain to brain through imitation.
We're going to talk a little bit about how we can help. If we aren't someone that can sit there and say I can pay people a shift differential for being on-call, we can help set examples. We can create memes through our organization that will make this experience better.
Another thing — if you're not familiar with Richard Dawkins, he's a very famous atheist. I first gave this talk in Salt Lake City in the United States, which is where the Mormons are from. It was a little awkward, but it's okay.
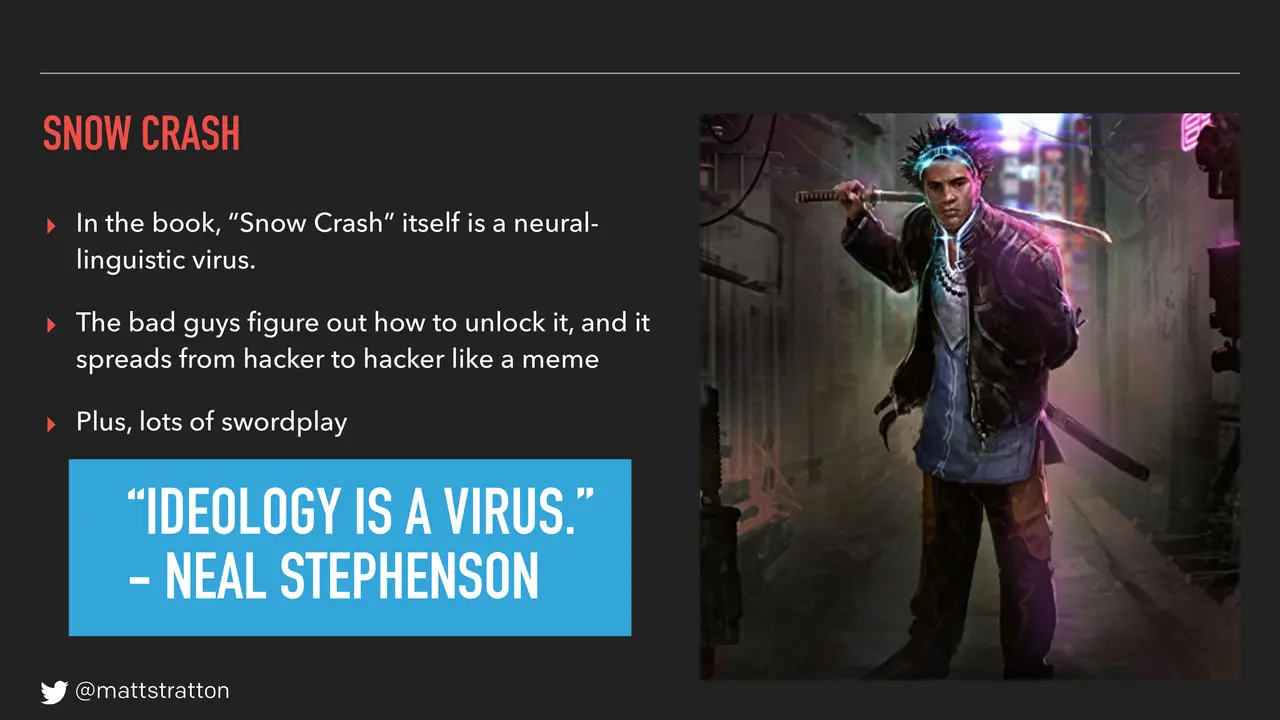
So if we think about this, memes are a way of evolving across generations. There's a fairly well-known — some might say it's a cyberpunk book, we could actually have a whole talk about discussing whether or not Snow Crash fits into the genre of cyberpunk, but let's say it does — book called Snow Crash. One of the ideas in Snow Crash is that neuro-linguistic viruses as memes evolved from generation to generation. In the book, Snow Crash itself is a neuro-linguistic virus, and the bad guys in the book figure out a way to unlock this virus and it spreads from hacker to hacker like a meme. There's also lots of swordplay so it's kind of a cool book.
Now Neal Stephenson, the author of the book, says ideology is a virus. Ideology is a virus. We're going to take these ideals of humane on-call and spread them through the organization like a virus.
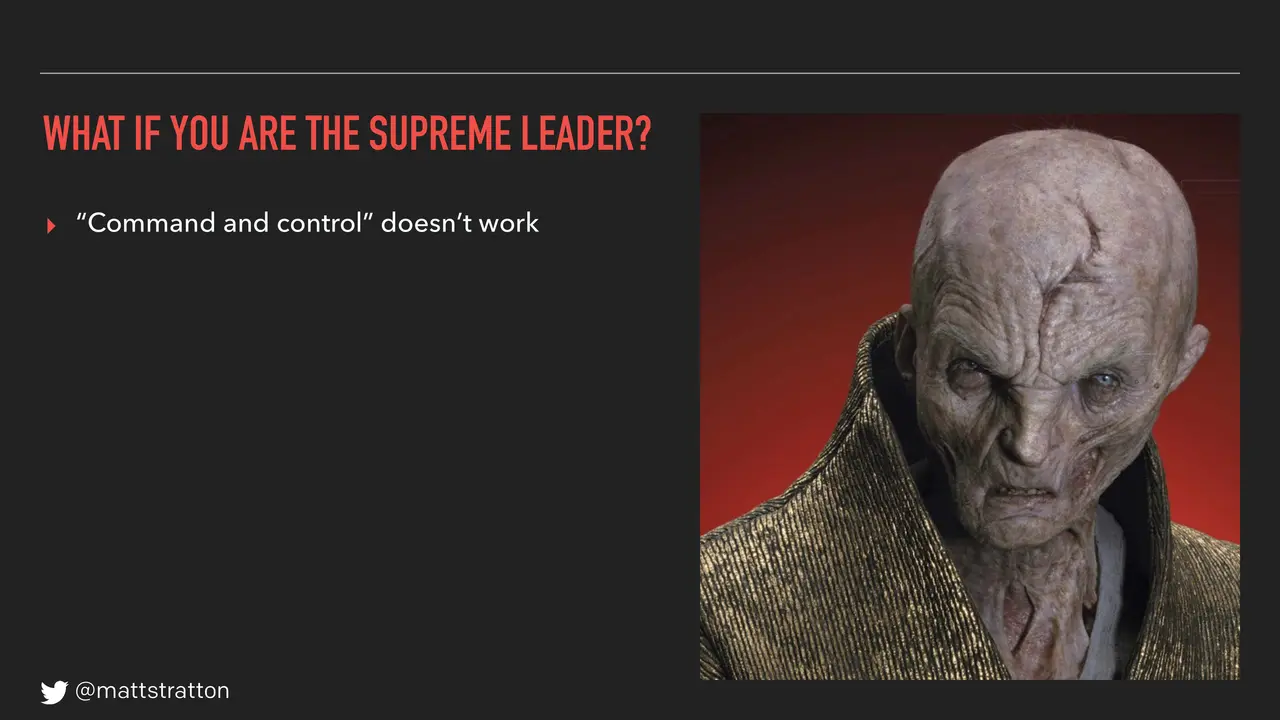
So we talked about this a little bit: everyone has different roles in an organization and your ability to affect change will be different depending upon your role. We're going to start as the supreme leader — you're some big bigshot manager, senior manager, VP, something like that. What are the things that a supreme leader can do?
Number one: learn first and foremost that the ideas of command and control don't work. Emily talked about this a little bit in her talk, about squads being empowered. The irony is that we like to think that command and control is effective, whereas almost every military in the world has abandoned this in favor of maneuver warfare, which is what Emily talked about — the command is "take that hill," not "take that hill this way." The sooner that senior management understands that command and control does not function, that's one of the best things you can do if you're in this position.
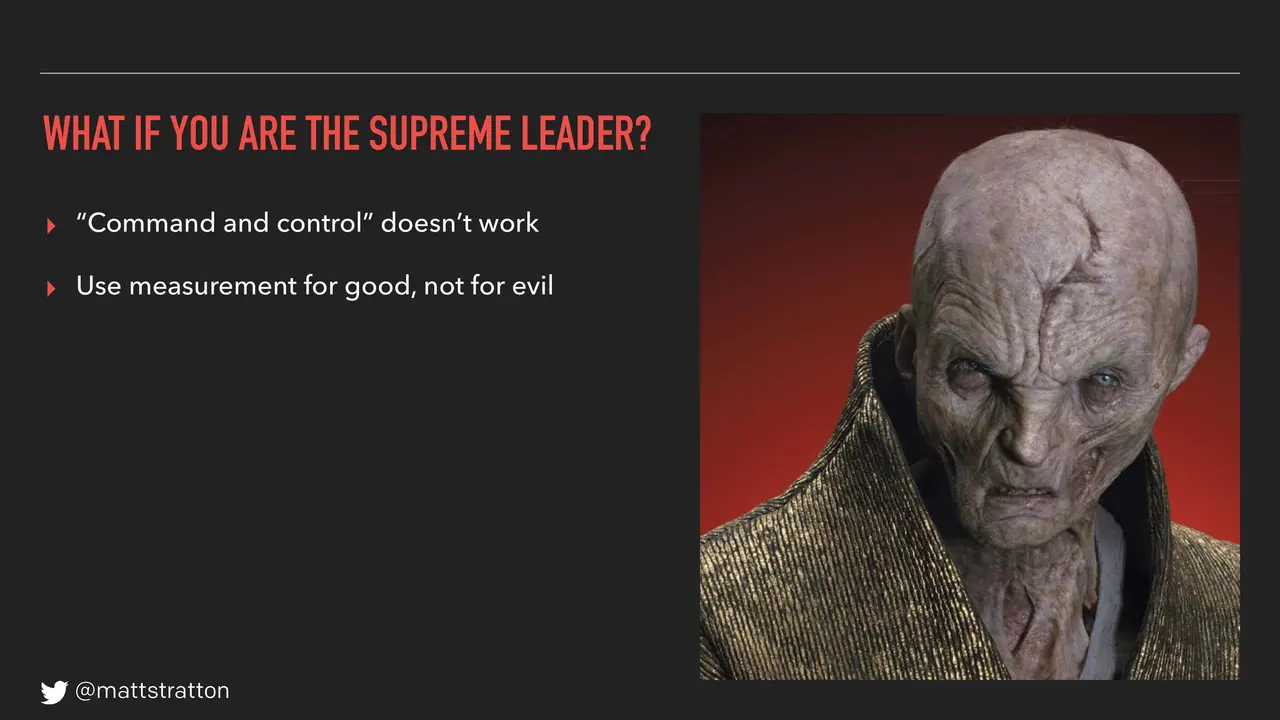
Using measurement for good, not for evil. This is a tricky one. Numbers are inherently neutral — they're not good or bad. The same numbers that we might use for measuring productivity can be a great thing. Hey, are we doing the right stuff? Let's reward the right thing. Guess what happens? The same number that helps you understand if you should reward can also be used to punish. We have a product at PagerDuty — the operational management health service — where because we can measure the operational health of your organization using a lot of tooling, we can look at it and say, hey, we know that people are going to burn out if the way that they respond to alerts starts to slow down. Because you know what happens when people start to get burned out — they respond to pages not as timely. There's a very specific reason that in that product we don't just give you those numbers; you have to work with us. You know why? Because we don't trust you to be good. Because that same number that says, "Hey, you're not responding to pages quickly, you're probably burning out" could also be turned around to be, "You're not responding to pages quickly, you're on a performance plan."
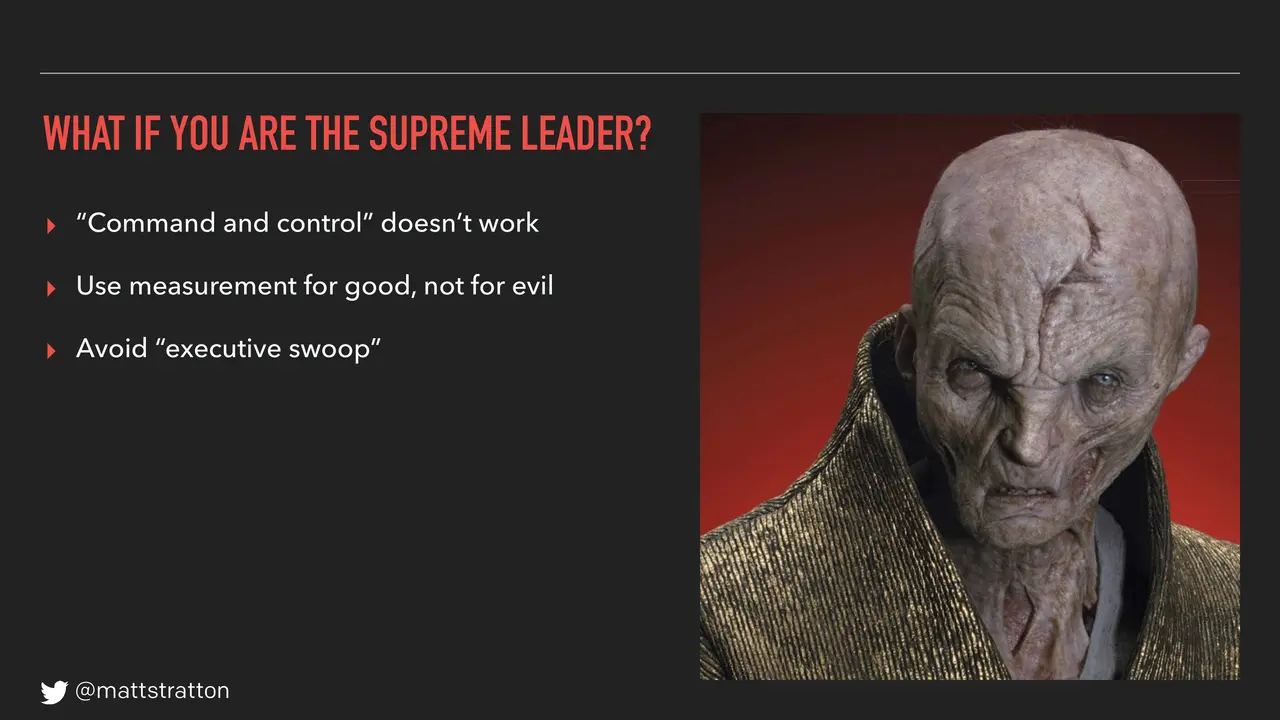
So use numbers for good, not for evil. And avoid what's called the executive swoop. I think Rachel touched on this a little bit when we talked about incident command. One of the toughest things about being an incident commander is when that CEO or management person gets on the call and does this, right? Trust your people. You hired smart people to do the smart thing — stay out of their way.
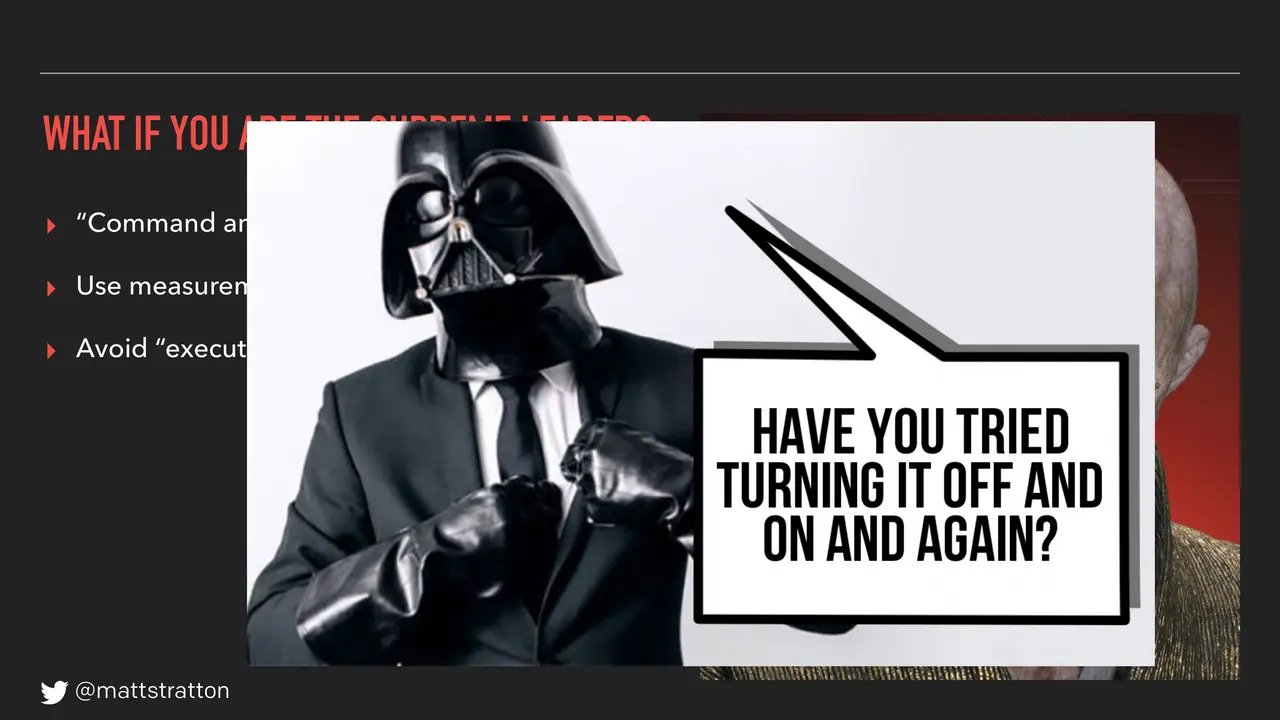
Avoid the executive swoop. We're gonna give you a little bonus tip. If you ever find yourself as an incident commander, here's one little trick we give in our training about how to handle executive swoop: when your executive comes in and starts demanding things, you turn to them and say, "Mr. Vader, are you taking over command of this incident?" And watch how quickly they get quiet.
Probably most of us in this room are not CIOs or senior VPs. Maybe you are — that's great; if you are I hope you're listening. We might have more middle management. Middle management's not necessarily used in a derogatory Dilbert term here, but folks who are managing teams. There's a lot of things that we can do as managers.
One of those things is to encourage a safe post-incident review space. Encourage the ability to have blameless post-mortems. Some of this may sound like common sense to you. You may be saying, "Matty, you're up here just telling us all the normal DevOps stuff." And my question to you is: why aren't you doing it?
Drive for a culture of learning. There's a great quote from John Cowie, who's at Chef now but was at CFPB for a long time. He said it's amazing what you can accomplish when the only ramification of making a mistake is that you learn something new. So having a culture of learning, it's okay to make mistakes because we learn from them. And again, just like your supreme leader — you hired smart people, get out of their way. Use your smart people.
So let's talk a little bit about that culture of learning. What does it actually mean? If we don't treat every outage or alert as something to learn from or to improve, we run the risk of something called normalization of deviance. In this case we start to accept alerts or degradation as acceptable. Our standards soften, we let things slip through the cracks.
This is kind of happening in the country where I live right now — we are actually as a country suffering from normalization of deviance, which is we are getting used to a lot of terrible things and that lets more terrible things happen. This can happen within your organization as well, because we say, "Oh it's okay for things to break, that's just how things are. That service always fails. Oh well."
In a generative performance-oriented organization we say that failure leads to inquiry. I didn't make this up — a gentleman named Ron Westrum from... and I have links to this, all the links that I provide in here I'm going to tell you about at the end so you can follow up on him. But also ask Dr. Nicole Forsgren of DORA who does the DevOps State of DevOps report — she's a big fan of Ron Westrum. Actually, to be quite honest, everybody in the DevOps community knows who Westrum is because of Nicole, so go ahead and follow her on Twitter and you'll learn a lot about how to rub numbers on your DevOps.
So here's the other thing to say: use the Force, even if you aren't a Jedi. This is the scenario of: hey, maybe I'm not the supreme leader, I'm not a middle manager, but what are the things I can do to affect change? What are the things we can do to set examples and maybe do things that are outside of my remit, outside of my job description?
So one of the things to think about is to review all the things. Andy Fleener, who is the platform operations manager at a company called Sports Engine, said they review every alert from the last 24 hours or over the weekend, every day. He says "no broken windows." What he's talking about there is what's called the broken window effect, which is normalization of deviance — the idea is that in a neighborhood if you leave a window broken people say, "Oh, it's okay for there to be broken windows," and this must mean that maybe crime becomes okay, and a whole bunch of other things start to happen.
At Sports Engine they have a meeting every morning and they go back and look at all the alerts that happened over the last 24 hours, so that everybody is aware of them. It's not pointing fingers, it's not even necessarily trying to solve for them — it's just an awareness thing. It's situational awareness.
So thinking more about normalization of deviance — the definition is that it's this gradual process where unacceptable practice or standards become acceptable. This deviant behavior is repeated if there is not a catastrophic result; it becomes a social norm for the organization. This is what we become used to — we become used to the bad things and they become the norm.
This happened to NASA twice. This is what happened with the Challenger explosion, and it also happened with Columbia, because it was, "Oh, this is OK, right?" These small things... In our case we're not having shuttles explode, hopefully. But what we have is that we accept alerts or degradation as acceptable. You know, there was that fun ignite yesterday about how developers and people are good at writing those Outlook rules and just putting them into their deleted items. How many people have worked in an environment where you get these false positive alerts and you just go, "Oh, I know I can ignore that because that's not real?"
When I was at Apartments.com we had — I could always tell when it was 1:00 in the morning if I was awake, because I would get the little page that said our main back-end database server was unreachable. The reason was because the database backup was running and that pegged the CPU for about an hour and a half. Here's the problem: if something actually happened to that database server during that time, nobody would pay attention because we'd say, "Oh, it's 1:00 a.m., DB zero is getting backed up, no big deal, that must be what it is." Normalization of deviance.
Question your metrics. We want to make sure that we're setting the proper expectations. We don't want to just expect five nines of reliability because well, five is better than four. Why do you need five? Are these metrics tied to a business outcome?
This is where you have to be bold, as Emily would say. You might have to question and challenge your product owners, challenge your management. Because often times we will get metrics and we don't know why. I used to have to run the PageSpeed metrics for an e-commerce site and present them to my CTO. I presented them to the board, and I said once, after I was doing this for a few months, "What's our goal?" And she said, "Not slower than last month." So there was no actual number around that, there was no "hey, if the page is faster then that leads to more conversion" or, more importantly, "this particular number means something."
Also watch out for inaccurate extrapolation. You might have data that suggests that if the page load time increases by a second, conversion drops by 50%. But that doesn't mean that if you reduce load time by a second it increases an additional 50%. Correlation doesn't necessarily equal causation and numbers don't move the dials in the same direction. A decrease in performance can have a decrease in conversion, but an increase in performance does not necessarily mean you'll have an increase in conversion. Our supreme leaders like to think that that's true. So try to find a way to actually tie your performance metrics to business outcomes.
So again, why are we using these numbers? What is the data that drives our incident process? When an incident gets raised, how do you know to raise one? I'll give you a clue: memory utilization on a server does not make an incident. It might be an indicator, but what matters is: can people buy shoes on your website — provided that you sell shoes on your website? If you don't, don't monitor for selling shoes on your website because it'll probably always fail. Are the metrics tied to business outcomes?
A lot of times people may have been in talks like this — this was really common at DevOpsDays a couple of years ago — the fun "how many people here revenue your products?" and everybody should have raised their hand. But it's true. Business outcomes are what matter. Our goal is not to keep the website up, our goal is not to ship features, our goal is to do the thing that makes our business or organization successful. And if you don't know what that is, you better darn well find out.
And this is the thing — Bridget and I will disagree often because I like to always tie things back to making money and she points out that not every organization is about making money. But I will ask you to extrapolate this for your own purposes: if you do not know how your organization makes money, go find out. Because if you don't know, you don't know how to make the right decisions for your organization. In the case of a non-profit, if you don't know how your organization shows value, if you don't know how the organization does the thing that makes it exist, you need to know. And correlation doesn't always equal causation — so those are key points.
Another thing you can do to make on-call suck less — I think that's trademarked by a competitor maybe, but that's okay — to make on-call more humane: think about simplicity. Do not over-design your systems. We heard yesterday about this idea called resume-driven development. Resume-driven development is almost always a recipe for on-call disasters.
This is what I call Stratton's Law, because I named one after myself. Stratton's Law of Catastrophic Predestination: at the heart of every complex resilient system it is the hubris that someone believed they could predict everything that could go wrong. Fate and the internet laugh at you.
The more resiliently you design your system, the more likely it is to cause a negative business impact. You don't always need seven layers of fault tolerance. Again, go back to those metrics — how reliable does the system have to be? Because by definition, the more fault-tolerant you make your system, the more parts it has, the more places there actually are for confusion.
Here are a couple of things you can do. Talk to people — these are your fellow humans. Ask your on-call how they're feeling during stand-ups. Maybe you're not an on-call person but someone who's on-call communicates with you during standup — say hi, how's it going, how has on-call been going, what was last night like? Give them the opportunity to mention that they might be burning out.
Think about who are your customers and what are their expectations. Your customers may be internal or external or both. Most of us, our real customers are probably internal at the end of the day — where we're providing some type of service for people inside our organization. Whose customer are you, and can you help them out? Who provides service to you — your network team, your storage team, your helpdesk? What are things you can do to help them out? And what are the perceptions of your team? This could be hard to dig into and it requires listening, but everybody who's done an on-call rotation has a little mental thought about every other team that they support and how helpful and supportive or not they might be. So try to understand the perception of your team with the people whose customer you are, and if it's not excessively positive, you've got some work to do.
So again, we're still talking about people. Consider contextual on-call. What does that mean? Let's say that you have a general ledger system that only works from 9:00 to 5:00 during the day. Does that mean that someone should be woken up at 2:00 in the morning if there's something wrong with it? You can have different levels, different necessities of on-call depending upon the context. You can also have different people being on-call depending upon the time of day or depending upon the context.
Again, the Golden Rule — which can go two ways. We know the one, which is "do unto others as you'd have them do unto you." There's also Wheaton's Law, from Wil Wheaton of internet and Star Trek fame, which is "don't be a dick." Keep that in mind when you're interacting with people. Treat them the way that you would expect to be treated, because in your organization you are somebody's customer and somebody is your customer. So think about how annoying the business is to you and try to not be that way to the people that support you.
And you know, you can bake cookies. So this idea of "cookie ops" — this actually just happened two days ago. How many people remember what happened to Slack two days ago? Maybe we didn't notice because we were all at DevOpsDays. But Slack had a pretty big outage and everybody freaks out. You know what? Our director of SRE literally sent them cupcakes. And they loved it. They tweeted about it. It made their day — well, maybe didn't make their day, it was a pretty bad day — but it made their day a little less awful.
Does that mean that you need to send cupcakes to GitHub when they have an outage? Not necessarily, you could, but think about the people within your organization. I had a peer of mine at one company — I was managing tech ops and he was managing DBAs — and he said, "Man, how come you always have the new laptop and the new phone?" And I was like, "Watch me at Christmastime sometime." Who goes down to the NOC with fresh cookies? Who in the summer brings homemade strawberry jam? Who goes and talks to them like they're people? He complains a lot and is really noisy and yells a lot when stuff is broken. So guess why I've got the new iPhone and you don't.
These things happen, they're true. We remember people who treat us nicely, who treat us like fellow humans. And volunteer to be an incident commander, like we learned about yesterday. If you are not part of a formal on-call, try to figure out a way to volunteer to help out as an incident commander. If you say "what's an incident commander," maybe that's the thing your organization should have, because that's a way to help share the load. One of the things that was really important that Gray touched on yesterday was that our incident command rotation is two days — that's not very stressful, it's not taking a lot. That's a way to help, and it's a way to help even if you aren't necessarily the person who can do all the things.
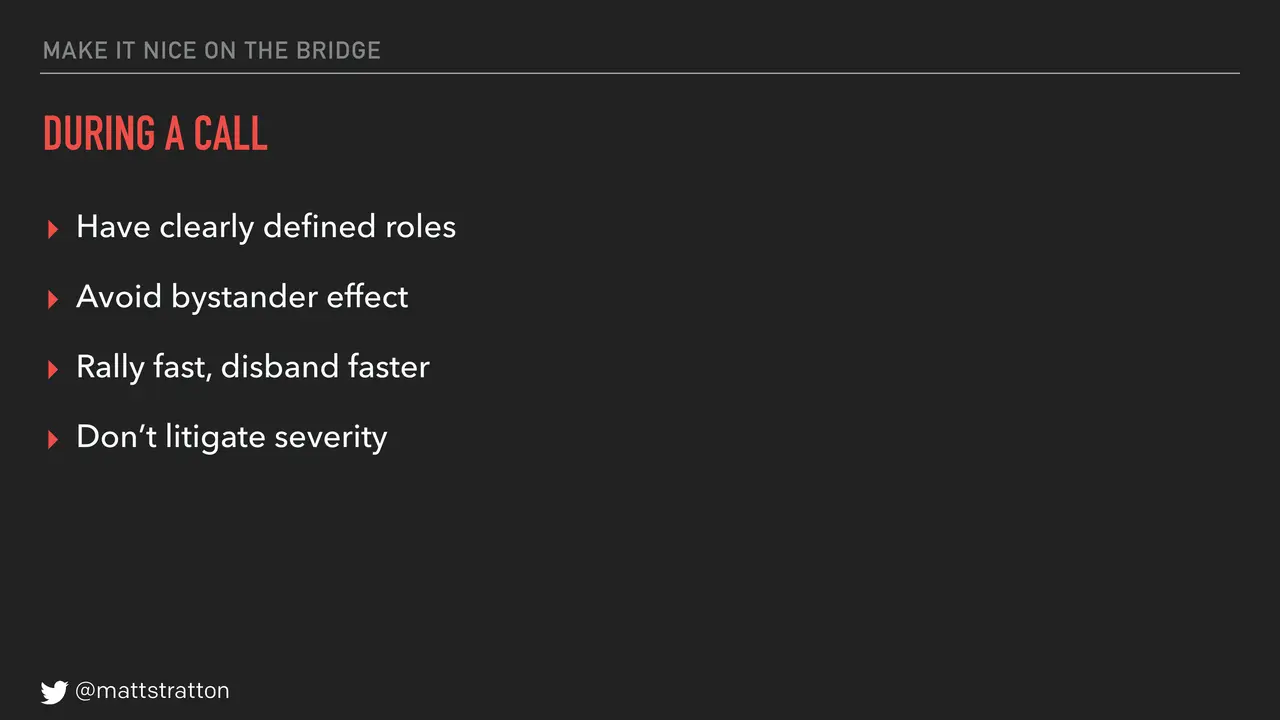
A couple things that can be helpful from a perspective of incident command, or maybe you don't call it incident command but just when you're having an on-call problem happen. Make it nice on the bridge that you're on. You want to do things like have clearly defined roles — know who's doing what. Whether you follow processes like we do with incident command and you have a scribe and you have SMEs, or whatever you may call them — tech leader, smart person, or whatever you call them — know what those roles are, have them clearly defined.
Avoid the bystander effect that Rachel talked about. Be very clear about assignments. These are all things that make being on-call at 2:00 in the morning better because stuff gets done faster.
Rally fast and disband faster. I believe very strongly in this. You want to get the right people involved as soon as you need to, but you want to get them off the call as soon as possible. You can get them back if you need them. How many people have ever been on one of those hundred-person problem bridges? How many people can imagine that they exist? How many people would never want to do that and are super glad they haven't?
Here's the fun thing about that hundred-person bridge: ninety-five of them are doing nothing and they're pissed off, sitting there going, "Oh my god, why am I on the phone?" And that does two bad things. That's bad morale and a bad experience for the ninety-five. It's also bad morale and bad experience for the five, because they're sitting there knowing they've got ninety-five irritated people watching their every move. So rally fast and disband faster.
This is tough — a lot of organizations don't like this. They want to get every single person who might ever have heard of the service on the call and will sit there till it's done. Not good.
And don't litigate severity. That means in the middle of a problem, whatever we decided the problem was worth, that's what it is. We're not going to argue about it. We've already figured out what a severity one is or severity two is; we don't argue about it when it's happening. We want to focus on solving the problem. Any conversations about should we be doing this, should we not be doing this — by the way, these are things that your executive swoops like to do a lot — you want to be able to turn that off and have a clear mechanism for making decisions. We like to call this the "is there any strong objection" rule. Rachel talked about a lot of this yesterday too.
A couple other things. Sharing is caring — share all the tests. What does that mean? Tests are for software engineers and SREs both. Or you might say they are for Dev and Ops both. I was trying to be hip by saying SWE, which by the way I only learned like two months ago was a term. Anyway, all functional tests that are used in pre-production should have a corresponding monitor in production. What does this mean? It means monitoring is nothing but testing with the time dimension. Similarly, if you're monitoring functionality in production, you need to have corresponding tests in the build and release process.
This is more uncommon than you might think, and the reason is because you have different groups who are in charge of those different things. Your QA testers are the people who are doing the pre-prod tests; your SREs maybe are the people who are monitoring in production. But here's my thought: if it's important enough that you're actually testing it — to say, if this gets released to production then X should equal Y or whatever — then why aren't you testing it in production to make sure it's still true? And likewise, if this is a thing that's going to control whether my pager goes off, you should be testing it before it gets released. This is the kind of thing that sounds like common sense but it's not so common. This is why a few years ago Damon Edwards said maybe we should rename DevOps "common sense." And you'll notice we have not, because it's not so common.
So here's the thing that you can do: every sprint, make a little resolution to yourself. In every sprint, do one nice thing. Help your responders in each and every sprint, even if it's not on a card. In every sprint or work unit, whatever you call them, add some value in some way to people who respond to incidents — even if there's no user story for it, even if it's not on a Kanban card, you rebel. All the scrum masters won't know what happened, it's okay.
What are some examples of things that you can do? And again, these may seem obvious to you, and I say: if they're so obvious, I assume you've already done them all. So great.
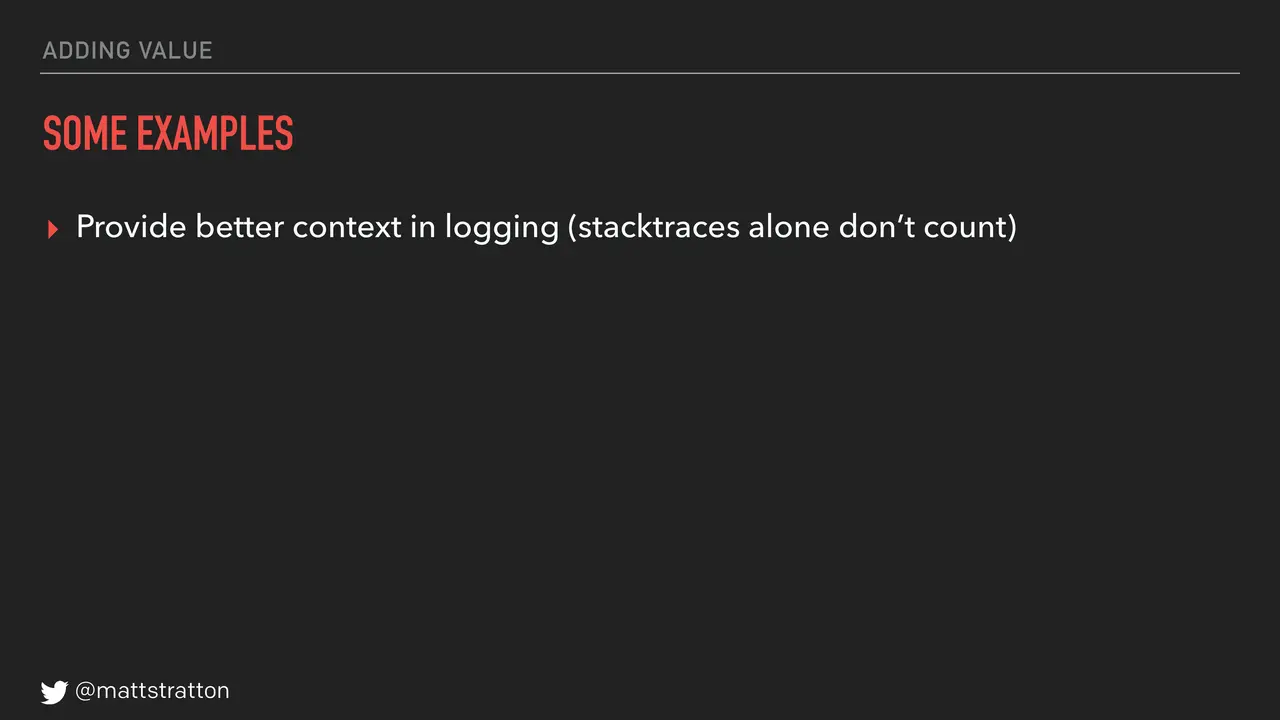
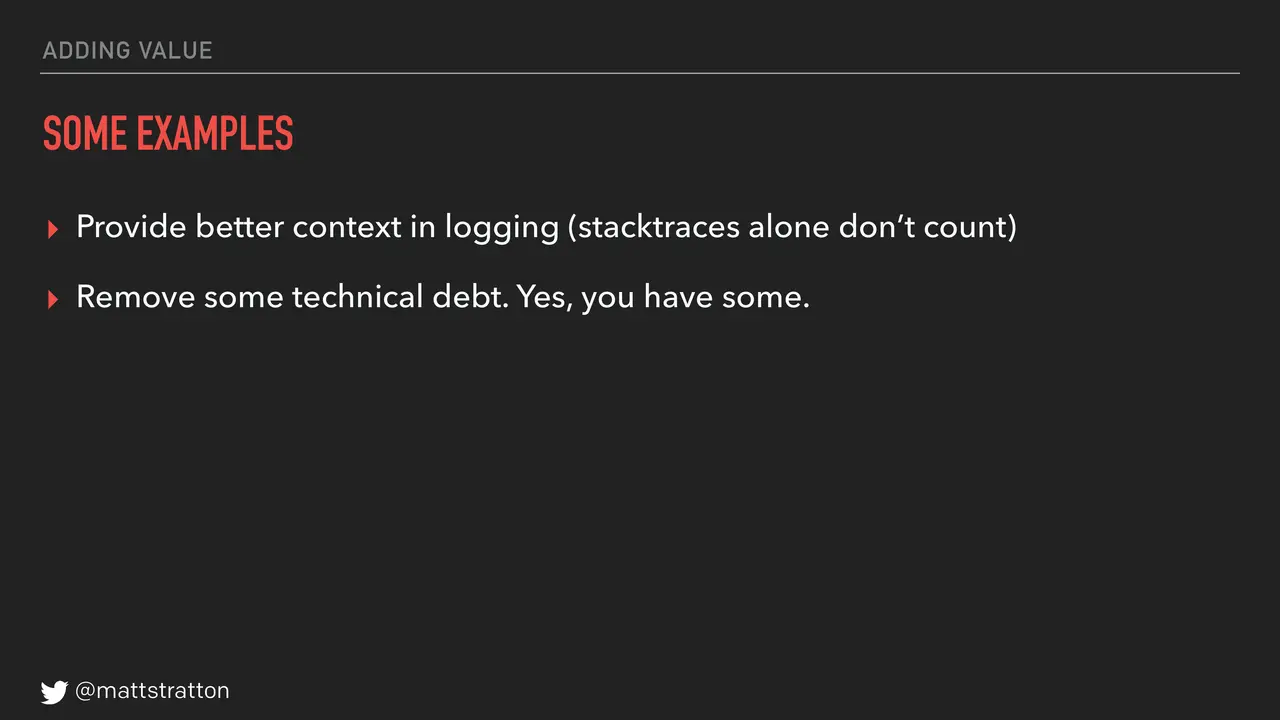
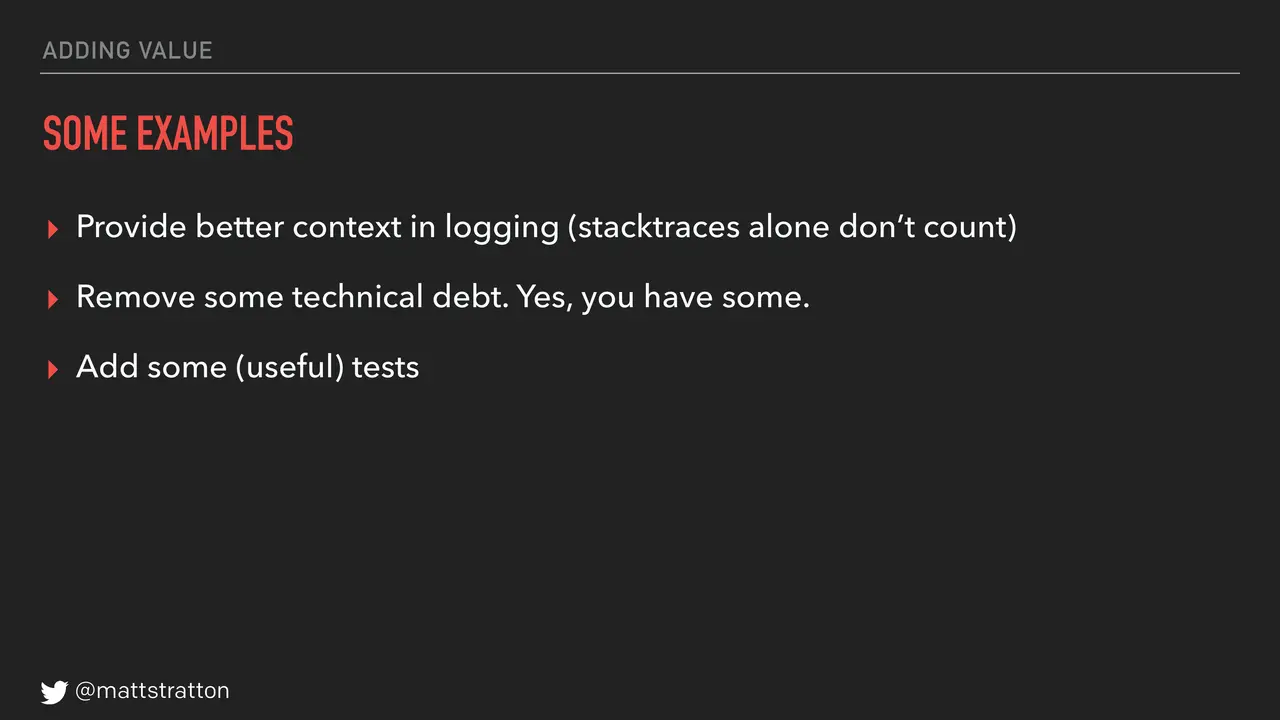
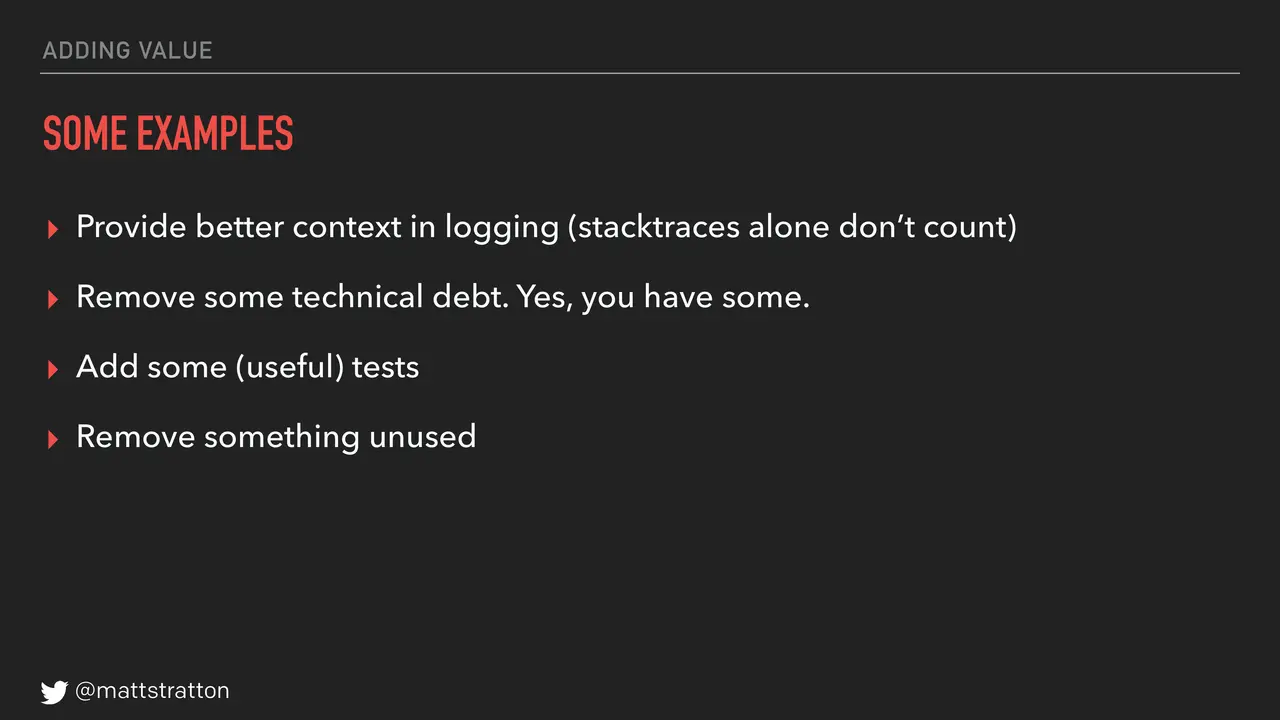
Providing better context in logging — stack traces are not context in logging. Stack traces are part of it, but give some context. Remove some technical debt. Yes, you have technical debt; you will find some, go remove some in every sprint. Also add some useful tests. The reason I put in that parenthetical of "useful" is to steal an anecdote from Jez Humble. He was working with an organization who had set a goal that said in every sprint they were going to add a test. What that meant is in every sprint they added a test that said "assert equals true." They added tests; they didn't test anything, but they sure did add some tests. So again, we all find ways to game the system. Make sure the tests you add are useful.
Then also remove something unused. More complexity means it's harder to troubleshoot. There's something in your codebase — this goes back to technical debt — that you've got something in there that isn't being used. Pull it out, get rid of it. Your responders will thank you.
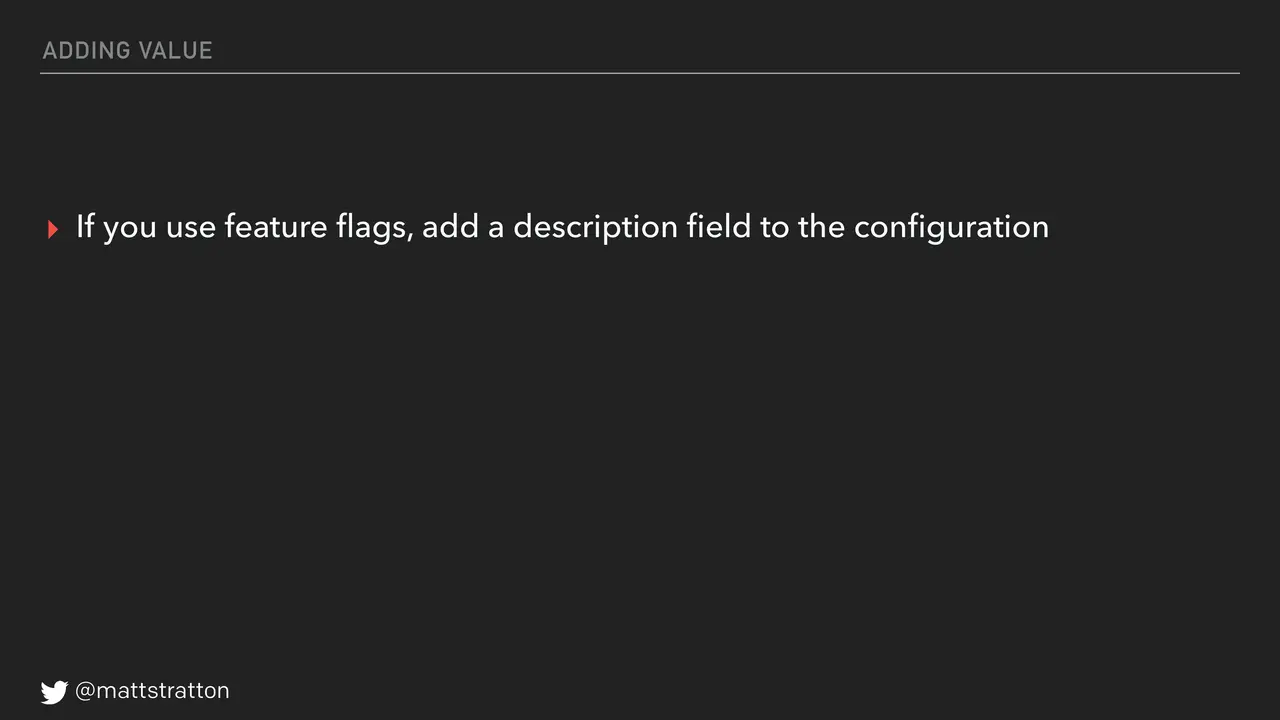
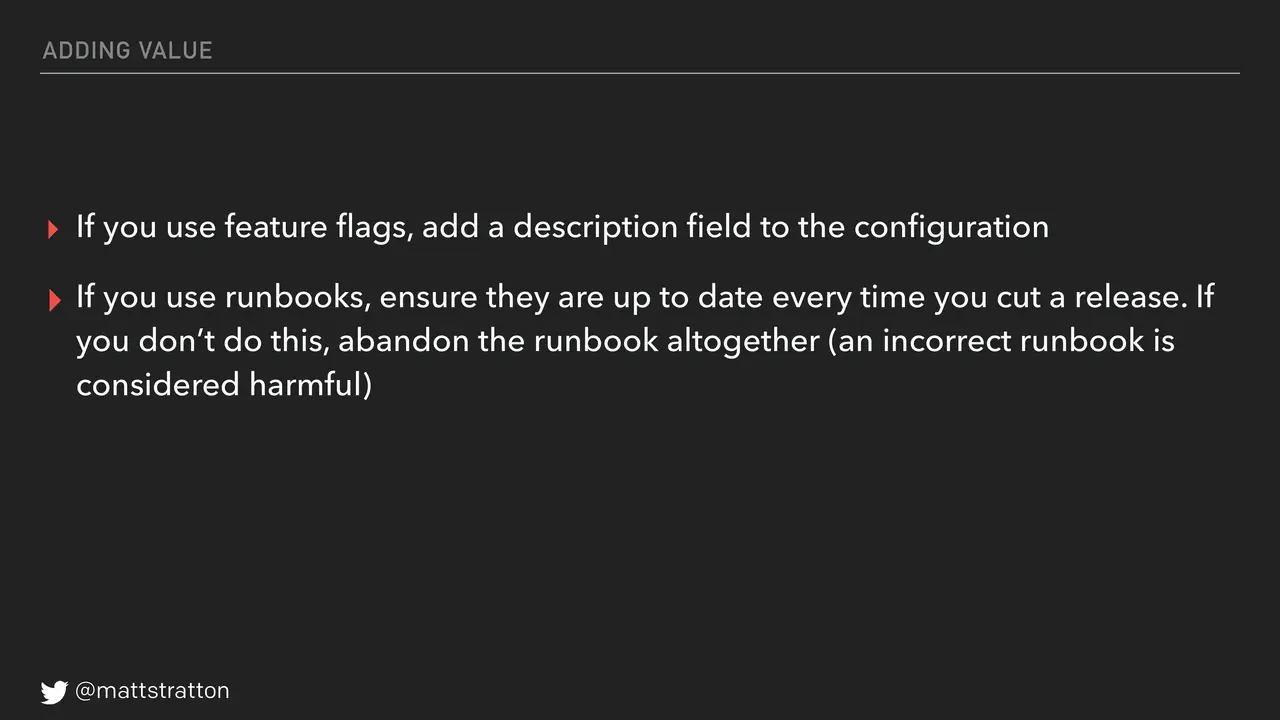
Other ways to add value: if you use feature flags, add a description field inside the configuration so people know what the feature flag actually does. If you use runbooks, ensure that they are up-to-date every time you cut a release. If you don't do this, consider abandoning the runbook altogether. An incorrect runbook is worse than no runbook. This is a little bit of a controversial statement, as I learned on Twitter, but I still think it's true. If you cannot keep your runbooks up-to-date, then don't have them.
And simplify, simplify.
So that should have given some ideas, some places to start — it's by no means exhaustive. The main idea I want you to walk away from is that making on-call for your colleagues and for yourself more humane is not something that requires a management edict. It's not something that requires a digital transformation project that's two years long. It requires changes that can be done with small changes in our day-to-day work. And what happens is, like a virus and like a meme, these things grow by adoption. You're setting an example to your fellow engineers, the people that you work with. They will take these on as their own as well and it will grow through the organization.
So I'd love to hear in open spaces out on the plaza and the terrace or whatever we call it — let's hear some fun on-call stories. I hear we actually have a fun open space that was pitched all about this. Those are some of my favorites. It's also my favorite interview question to ask.
This is the slide to take a picture of, so this is where the deck will be linked on my Notist. And the only reason I say that is not because I think my slides are so amazing that you're going to want to look at them over and over again, but because of the next slide.
The next slide is just a bunch of links, but because I do have a couple slides — if you go to Notist you'll find them there, as well as the links. These are a couple of the resources you might find helpful. "Improving Your Employee Retention with Real-Time Ops Data" — that's a webinar that covers all of the data that we did at PagerDuty. Then remember back at the beginning of the talk where I said we did this survey with all these IT responders — that's a blog post that I wrote on this topic. And talking about normalization of deviance, the study of information flow, is Ron Westrum. If you haven't read Snow Crash, if you choose to read it, we did an episode of Arrested DevOps. I think that was just Bridget but anyway you should check it out. And as Rachel pointed out yesterday, PagerDuty open-sourced our incident response docs. I recommend checking that out. They are literally open-source so if you go to response.pagerduty.com it's a very pretty web interface for looking at our docs, but there's also a link to the GitHub repo and we do accept pull requests.
So thank you. Any questions?
I'll be around the rest of the day so I'd like to hear your stories and think about things you've done.
So a question: assuming that the team you're working in is reluctant to set any formal "we provide service during these hours," and yet they call you anytime they feel like that should be working and it's not working, what would you suggest?
So — if I just want to make sure I got the question right — you have a team that works during business hours but you have customers that assume you work at all hours, and there's no SLA? You don't have an SLA, so this is an informal understanding. Part of that goes — again, the hard part of this is I'm always going to go back to: you have to talk to humans. As you say, you don't have a formal SLA, and I don't expect that means you have to write up a big document, but it does seem that there's a misunderstanding of expectation. The thing I would look into is: where did that come from? You have one expectation on your team, which is "we work this way," but somehow the expectation is that they expect something different. Try to understand why. And I'm not saying be super empathetic and work 24/7 because they need it, but do a little thought around where did that come from, and maybe have that conversation: "Why do you need this 24/7?" Then, that being said, if there's business value to it — what is it gonna cost? It's like, "Hey, this is something we can do but it comes at a cost to the organization; we have to figure out how to do that." And one of the ways you can help is to get that other team that's asking for this involved in helping, right? Because it's collaborative. Even if they're your customer it's not necessarily just a dish-off. It's not just "oh well, this thing is broke." It just comes back to conversation, which is tough. And sometimes it does require those middle managers to get involved to help set those expectations. But I would still go back to: how did that big disconnect happen? Why does one team think it's a 24/7 service and the other one thinks it's not?
Thank you. Any other questions? Okay, let's go. Thank you very much.