Fight, Flight, or Freeze — Releasing Organizational Trauma
DevOpsDays Copenhagen 2019 · · Copenhagen, Denmark































When humans are faced with a traumatic experience, our brains kick in with survival mechanisms. These mechanisms are the familiar fight or flight response, but can also include the freeze response - which occurs when we are terrified or feel that there is no chance of escape.
In this talk I will explain the background of fight, flight, and freeze, and how it applies to organizations. Based on my own experiences with post-traumatic stress (PTS), I will give examples and suggestions on how to identify your own organizational trauma and how to help heal it.
Sufferers of post-traumatic stress continue to feel these fight, flight, and freeze responses long after the trauma has passed, because our brains are unable to differentiate between the memory of trauma and an actually occurring event. When activated or triggered, the brain reverts to these behaviors, which are then expressed in the person’s body (through posture, disassociation, muscle tension, etc).
The same can occur to organizations - once an organization has experienced a trauma (a large outage, say) the “memory” of that trauma leads to a deregulated state whenever activated (by symptoms of similar indicators, such as system alerts, customer issues, and more). The organization will insist on revisiting the same fight, flight, or freeze response as the embedded trauma has caused, which, like a triggered post-traumatic stress sufferer, is a false equivalency.
One of the treatments for post-traumatic stress is Eye Movement Desensitization and Reprocessing (EMDR), in which the patient’s difficult memories are offset with a positive association that is reinforced through external stimuli. The same can be done for organizations - removing the inaccurate traumatic associations of previous outages and organizational pain through game days, and other techniques, we can reduce the “scar tissue” of our organization and move forward in a balanced manner.
Resources
Transcript · 4,006 words · ~20 min read
Lightly edited for readability from the video’s captions. Download as text
Good morning, DevOps Days. I am really excited to be here. I have a personal connection to this city and this country. My aunt has lived here since before I was born. I was here when I was in my teen years and then didn't come back again for 30 plus years. I was back here in October and I decided to come back again now when I was invited to come be part of this event, so I'm very excited to be here.
Last time I was here I got the Danish flag tattooed on my arm. I don't know what I'm gonna do to celebrate this time, but we'll figure it out.
Again, my name is Matty Stratton. I'm the DevOps — or human ops — advocate for PagerDuty, and that's about the only time you're gonna hear me reference PagerDuty in the rest of this talk. If you're interested to know more about PagerDuty, let's talk during a break, it'll be fun. But besides that I'm not here to talk about my company. I'm here to talk about something that I call organizational trauma. This talk is called "Fight, Flight, or Freeze: Releasing Organizational Trauma." What does that mean? Well, for the next half an hour I'm gonna let you know.
Just a little quick warning: this is a discussion of trauma and post-traumatic stress. I don't talk about any specific traumatic experiences or anything, but we do talk about post-traumatic stress and some treatments and things around that.
And another disclaimer: I'm a trauma survivor, but this is the important part — I'm not a mental healthcare professional. So none of this is mental health advice, it is not professional medical advice. We're gonna be talking more about organizations and how your company, your organization, deals with incidents, outages, or disruptions, using the metaphor of post-traumatic stress and where these things come into play.
So let's talk about zebras. Trust me, this will get somewhere.
If we have a zebra at rest — Mr. Zebra here, he's just chilling out, he's eating some grass out on the Savannah, there's no threat of predators — it's operating within what we call the rest and digest function of the parasympathetic nervous system. There are two parts of the nervous system: the parasympathetic and the sympathetic. The parasympathetic nervous system is rest and digest. The zebra's systems are focused on things like eating food, digesting the food, maybe thinking about mating with other zebras. Everything is cool and fine.
Now we introduce a lion. This changes things a little bit. If a lion starts chasing the zebra, there are direct physiological changes that occur with the activation of what's called the fight-or-flight response. This kicks in the sympathetic nervous system. Things happen like the heart rate increases, a lot of adrenaline is released into the bloodstream, the pupils dilate, cortisol is also released into the bloodstream, blood pressure increases, and basically any non-essential functions shut down. Digestion shuts down because right now the zebra's nervous system is preparing it to literally run for its life.
So if the zebra gets caught, its nervous system shuts down — it's basically out of options. This is the freeze response, and the zebra fundamentally plays dead. The lion says okay, caught the zebra, zebra is dead, gonna leave the zebra over here, maybe go try to catch another zebra.
And what does the zebra do when it's released? The zebra actually gets up and it shakes itself out. Its whole body shakes, and what's happening there is it's releasing the traumatic experience that happened, just through that shaking. The zebra then returns to a resting state, goes back to its rest and digest, and then everything continues.
Now here is the most important thing you're gonna learn at this entire conference: humans are not zebras.
If you learn nothing else over these next two days, it's that we are not zebras.
What does this mean? All mammals have the autonomic nervous system, which is the one that we just talked about — the fight-or-flight and freeze response. Humans have this thing called a prefrontal cortex, and this is unique across all mammals. Only humans have this. And this is usually an advantage. The prefrontal cortex is where executive function happens. This is where we can tell the difference between good and bad, same and different, understanding consequences. This all comes from our prefrontal cortex.
But here's the downside: the prefrontal cortex is also where we replay traumatic experiences over and over again. You may have heard that humans are smart and we have very advanced brains. I'm here to tell you that our brains are actually kind of stupid. Our brain, our prefrontal cortex, cannot tell the difference between real and perceived trauma. This is why when we've had a traumatic experience, when our brain relives it, we have the same physiological responses in our body as to the real trauma. This is the fundamental difference between humans and the rest of the mammal world — we relive these traumas.
Dr. Peter Levine has said that animals in the wild are not traumatized by routine threats to their lives. Humans, on the other hand, are readily overwhelmed and subject to symptoms such as hyper arousal, shutdown, and dysregulation. This is the difference between us and animals in the wild. Traumatic things happen to animals in the wild all the time and they move on. We don't do that.
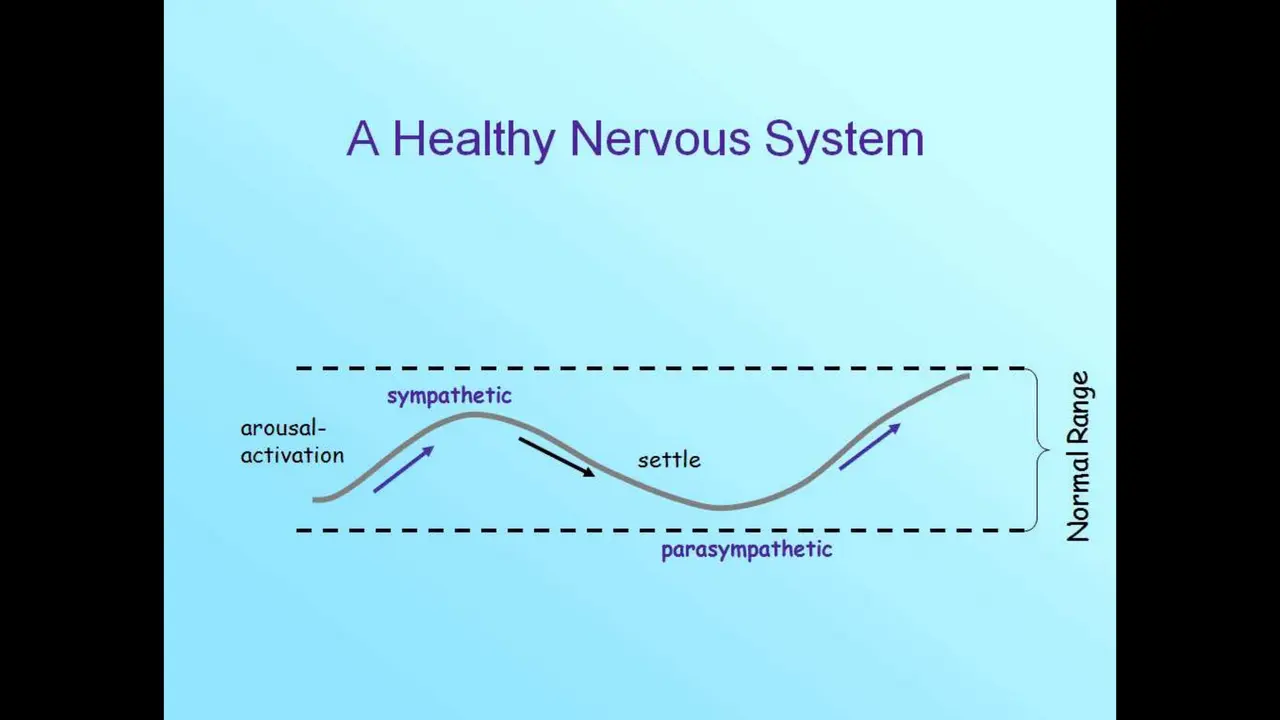
When a very traumatic experience happens to us, we become dysregulated by it. So we're gonna talk about something called the window of tolerance. The window of tolerance is a zone of emotional arousal that's optimal for well-being and effective functioning.
Fundamentally, in a healthy nervous system, something will happen, there's arousal, there's activation, something happens and we spike our sympathetic nervous system — fight-or-flight response happens — and then it's over, we kind of move back down, we settle into parasympathetic rest and digest. In a healthy nervous system, we're operating within this window of tolerance, which says it's okay that we come up but then we come back down, and then we come back up, and we come back down. The parasympathetic is rest and digest, conservation of energy, whereas the sympathetic is fight-or-flight.
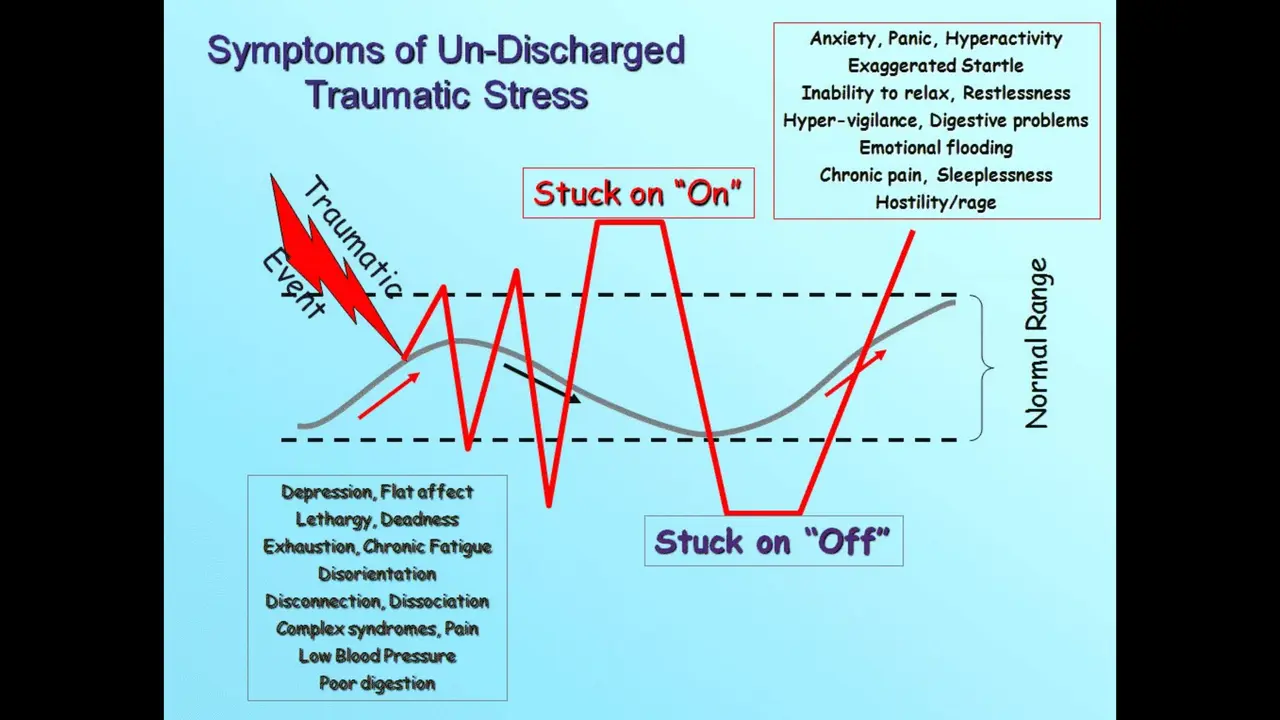
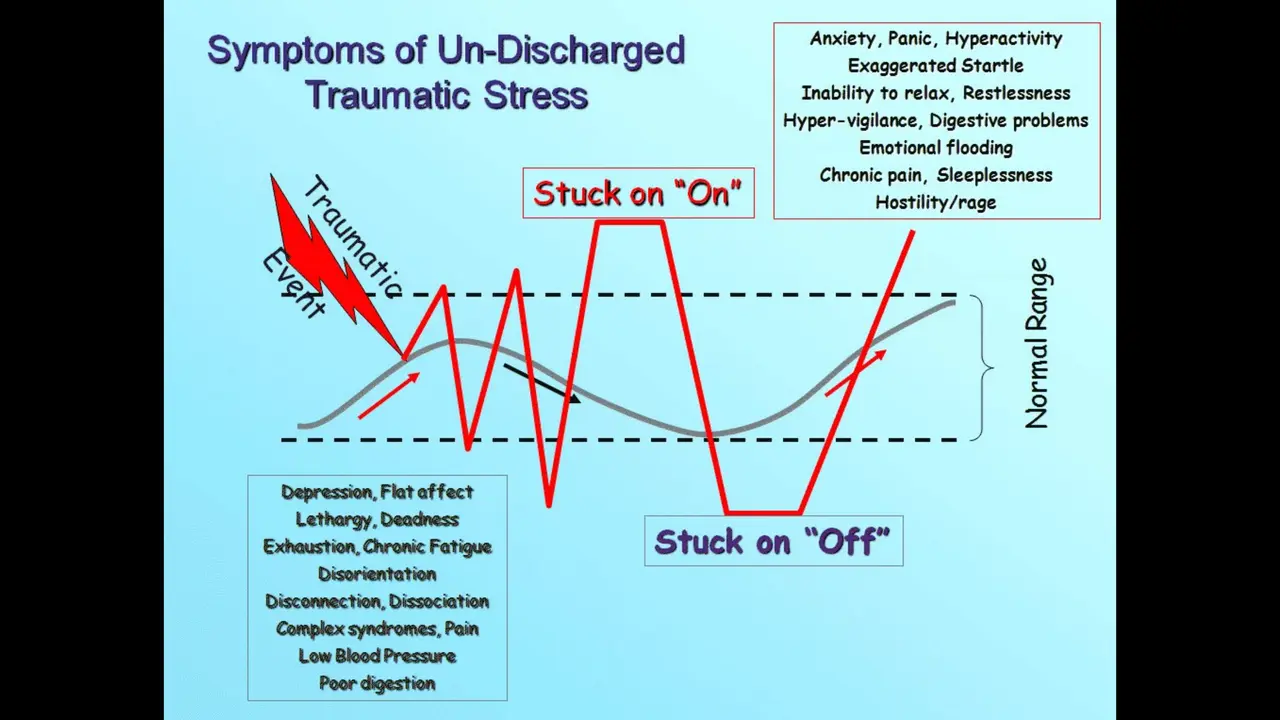
Now what happens when there is a traumatic event? Our nervous system becomes dysregulated. We operate outside of our window of tolerance, and it can be very spiky, or we can become stuck on or stuck off.
The symptoms of being stuck on include things like anxiety, panic, hyperactivity, digestive troubles, sleeplessness, hostility. The symptoms of being stuck off include depression or lethargy — and notice we also see digestive problems there because our digestive system is very sensitive to being dysregulated.
Hyper arousal is the fight-or-flight response, that's being stuck on. Hypo arousal is similar to the freeze response, so we're basically stuck always fighting and flighting, or we are always frozen.
Now, trauma is not simple. It occurs when your solution, your active response to the threat, doesn't work. The nervous system has been overwhelmed. This is subjective — it can result from real or perceived threats. Our prefrontal cortex can't tell the difference between an actual threat or a perceived threat, and therefore it kicks off the exact same physiological response and our body will react in the same way. It is subjective and relative. What I perceive as overwhelming, or my capacity to deal with it, is going to be different than yours.
How does this apply to an organization though? This is DevOps Days, not mental health days, right? Trust me, this is all laying groundwork. Now we're gonna actually talk about how this applies to your organization, your company, your team.
Let's go back and look at our window of tolerance again, and let's start to think about how this could apply to an organization. If we say that the traumatic event in this instance would be an outage, an incident, or some type of major disruption of service or business, what can happen? Just like as an individual, we could get stuck on or we could get stuck off. The same thing happens to teams and companies.
First, there could be hyper arousal, which is the fight-or-flight response — being stuck on. If organizations get stuck on, what you run into is effects of constant vigilance. We are watching everything all the time, we're expecting bad things around the corner, we're expecting this to happen, we're looking over our shoulder all the time. Being hyper aware of threats takes energy away from innovation and driving change forward.
Often times this is reflected in how leadership handles incidents and outages. In organizations that are hyper aroused, you'll see a lot of military metaphors, a lot of "let's talk about peacetime versus wartime," "we're under attack." Using these terms tends to reflect an organization that is hyper aroused.
The other side is hypo arousal, which is the freeze response. We see this a lot too — organizations that are stuck off, they can't move forward because they are afraid of making any change. We're stuck here, we don't move, because if we move, bad things happen again. Lack of innovation, lack of change. And the reality in today's world is you have to be able to innovate. It doesn't mean "move fast and break things," it doesn't mean just do whatever you want. But the world we live in today demands that we are responsive to the needs of our customers and our users, and anything that is causing us to be unable to be responsive in the way that our business requires is a liability.
So we think about inappropriate response — things happen and we respond to them, that's not inappropriate, that's doing business. But when we are either stuck on or stuck off, our responses can be counterproductive and get in the way.
We like pattern recognition, right? We're humans, that's what we do. We like to see patterns and then say "this looks like that." Before I was a DevOps advocate — or whatever we call me this week — I spent two decades working in technical operations. I used to say you could tell a good sysadmin because they would sit there during an issue and say "hmm, I've seen this before." The problem with that is, just because we see a pattern that seems similar does not mean that it's the same as before. The systems we work with, the sociotechnical systems, are very complex. Just because one symptom looks like another one does not mean that the experience is the same as last time.
I'll give a fun example, and this is a place where you can laugh at the Americans. Let's talk about shoes and airplanes. In December of 2001, a guy named Richard Reid tried to ignite explosives that were in his shoes on a flight from Paris to Miami. As a result, the TSA — the Transportation Security Administration in the States — decided to start randomly screening passengers' shoes, because somebody tried to do this, so chances are someone will try to do it again. Then in 2006, the TSA mandated that all travelers in the United States have to take their shoes off to go through security, unless you pay some extra money and then you don't have to take your shoes off anymore.
So what happened here? We saw a pattern. The pattern that we saw was: a person who wore shoes tried to do a bad thing, therefore shoes are bad. We're looking for this pattern, but what we're seeing is that things don't always look exactly the same way.
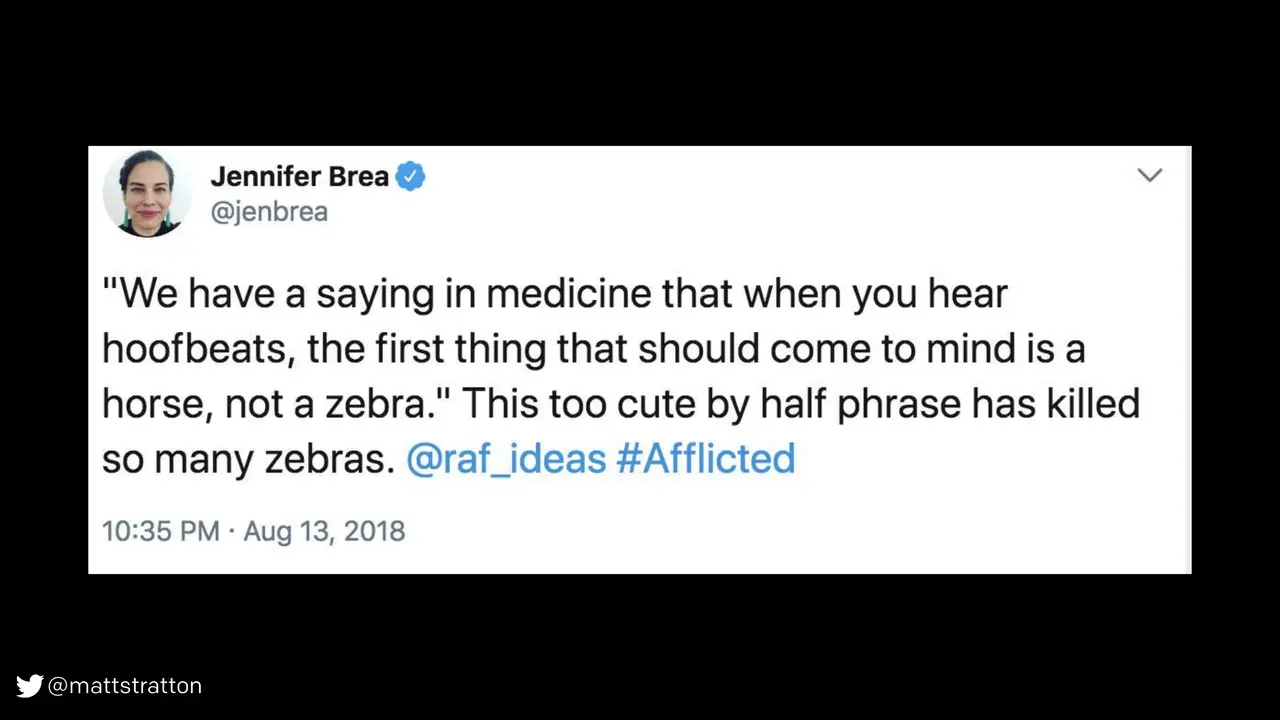
I really like this tweet from Jennifer Davis, who says: "We have a saying in medicine that when you hear hoofbeats the first thing that should come to mind is a horse, not a zebra. This 'too cute by half' heuristic has killed so many zebras." What does this mean? We need to stop jumping on the first root cause.
How many people, when you're doing incident response, you're doing a post-incident review, are used to the term "root cause analysis"? How many people, when you have an incident, one of the things you have to do in your form is to identify the root cause?
I'll tell you the problem with the term root cause and why we prefer the term "contributing factors." The problem with root cause is it implies that there was one root cause, that one thing happened that caused this incident or outage. Again, our systems are complex, so it's rarely one thing. If you want to do a little bit of research, there was a really great write-up on the Boeing 737 MAX situation that happened recently. There were so many contributing factors, but if we look for the root cause we say "software bug." But it wasn't just the code — it had to do with financial implications and incentives, it had to do with government regulations. There were many contributing factors.
So what happens when we look for a root cause? The first contributing factor we find, we say "aha, solved it, it was this." This is why, because every incident is different, even if it looks similar to the last time we had a problem like this. Things have changed, the customers impacted have changed, the individuals involved have changed. Everything is constantly in motion, as Yoda would say, constantly in motion. Our systems, things are always changing. It's okay because a lot of times the hoofbeats are coming from zebras, they're not just coming from horses.
So what can we do to understand the window of tolerance for our organization? How can we identify when our organization is becoming dysregulated? What are some of the symptoms?
We talked about a few of them, which would be always being focused on what could possibly be going wrong. There's a term we use in the industry sometimes called analysis paralysis, which means before we're making a change, we want to think about everything that could possibly go wrong. I've got news for you — you are never going to think of everything that could possibly go wrong.
There's something called Murphy's Law, right? Murphy's Law is "what can go wrong will." There's an extension to Murphy's Law called Finagle's Law. Finagle's Law is "what could possibly go wrong will, at the most inconvenient time." The more that we think about analysis paralysis, the more we realize we're just not going to catch everything.
So just as we talked about how the difference between animals and humans is how they respond, I believe that resilient organizations are not traumatized by routine threats to their mission or business. Non-resilient organizations are readily overwhelmed and they encompass those symptoms.
I want to talk a little bit about that word "resilient." Is anybody familiar with the term resilience engineering? One of the things that's basically happened is, as we often do in IT, we discover that other industries and other disciplines have been doing this much better than we have for a long time. The practice of safety science and resilience engineering has been around for a long time — we've only just started to discover it now.
There's a difference between robustness and resilience. You cannot build resiliency into your systems with technology. You can build robustness. Robustness is what we build into our systems by design. Resilience is what kicks in when we extend beyond the robustness that we built, and resilience requires humans. As much as we love all of the automation and DevOps, we still need the people, because the people are the ones who come in to help make our organization more resilient.
So this is why we're gonna talk about how we help people make your organization more resilient. We have to think about how we regulate — how do humans and organizations take a dysregulated state and become regulated?
One of the treatments for post-traumatic stress is something called EMDR, which is Eye Movement Desensitization and Reprocessing — and that's why we call it EMDR, because those words are hard to pronounce and remember. What happens in EMDR is the patient has their vision stimulated, their hearing stimulated, or tactile stimulation that associates a regulated state. This is basically creating a physiological response to being regulated, so that when traumatic memories and experiences are revisited there's a physiological association with that. The association is being reinforced through external stimuli.
How do we do this for our organization? Well, you can't put little blinky lights on all your engineers and little special headphones, but we can take some of the same ideas and apply them to how we work so we get the same result. The idea is creating a positive association through physiological stimuli.
One of these is game days. We want to make an association between outages and issues and a safe place, a place that doesn't cause stress. Game days can help us do that, but they have to be done properly — you have to keep them low stress and safe.
A game day is a planned exercise within your organization where you execute incident response. You intentionally say we're going to practice an outage now. What we're doing with this is we're trying to create a positive association, because we don't have positive associations with incidents and outages. How many people have been on call? What happens in your body when PagerDuty goes off? You tense up, the adrenaline runs, and everything about being paged is designed to actually cause this physiological response. This is why one of the things that I always recommend is to rotate the alert sound on your phone for your on-call system, so you aren't always hearing the same tone. You know how it is when you've got your PagerDuty sound on your phone and then somebody else has that as just their text tone, and you're next to them on the train and they get a text — your body reacts. So this is why you want to continually rotate those things.
When you're running a game day, there needs to be some guidance. The point of the game day is not to test how good your engineers are at solving problems. The point is to say let's practice our response, let's practice how we do this in a safe and calm way, so that when it happens in the middle of the night we have this kind of muscle memory that this is an okay thing.
This also applies when we think about planned failure injection. This is a variant on game days and an aspect of chaos engineering — we are going to intentionally cause failure in our system, which hopefully has robustness and resiliency built in. When we run planned failure injection, we want to run it like a real incident.
At PagerDuty we have something we call Failure Fridays. On Fridays we take a system and we shut off part of it to see how do we respond to that. We follow our complete incident response process. Everybody involved knows what's actually wrong because we made it be wrong. However, we have our incident commander, we have our bridge, we write everything up, and we even do a post-incident report afterwards. The reason for this is because it's giving us practice, it's giving us this ability — hey, we do this all the time, so when it's 2:00 in the morning and a high severity incident comes in, we aren't stressed out about having to do our incident response process. We know how to do it, we're totally calm about it.
This is also why if something comes in as a high severity incident, we run it to its full course, even if we discover that it was not actually an incident.
We need to process failure. Is anybody familiar with the idea of blameless post-mortems?
When we are doing our post-incident reviews, we want to have an approach that is blameless. The idea is that during a post-incident review — our post-mortem — is not to figure out who messed up and point the finger. Here's the reality: people are going to continue to mess up. If people are going to be punished for failure, that does not mean that people make fewer mistakes. It means they become experts at hiding their mistakes, and now you're in real trouble because you don't actually know what's going on in your systems anymore. We like to say: you can't fire your way to reliability.
What we want to do is, instead of trying to keep humans from making mistakes, figure out: what was it about the system that allowed this natural human error to cause an incident?
That's just the beginning. The next thing that's really important when we look at our post-mortems or post-incident reviews is we have to process them. It's not just enough to fill out the form — the incident review form with all our checkboxes for root cause analysis and all this stuff — and then shove it into Confluence or into our wiki somewhere and nobody ever looks at it. I call that a write-only post-mortem and it does not help anybody.
We want to think about them as stories. Post-mortems should raise more questions than they answer. We need to discuss them outside of our team, outside of the people that were directly impacted by the outage or directly involved in the resolution of the incident, because people who were not directly there are going to have a different take on it.
A fellow named John Paul Reid, who wrote his master's dissertation on post-mortems, discovered that the larger the organization, the less likely teams were to share their post-mortems outside of their team. And the irony is, the larger the organization, the more important it is to share the results of these post-mortems, because this is how you get more insight and more impact. We want to think about them as telling a story and seeing them through, because otherwise it's just more unprocessed trauma.
Another thing that comes up when we talk about post-traumatic stress is something called somatic experiencing. Soma means body. Traditional approaches to post-traumatic stress is talk therapy — you sit down and talk to a therapist about it and work it out. Somatic experiencing operates in the opposite direction — it starts with the body and the physiological response, and that affects the emotional response.
How does this affect incidents and outages? This is similar to looking for root cause first. This is why we first look at what the impacts are and understand what the things are that happened, rather than immediately looking for root cause. If we start looking immediately for root cause, we're gonna find one, but it's gonna be the first thing that we find, not the thing that we actually experienced.
I'm running out of time, so I'm going to skip over a bunch of stuff I had about cognitive distortions — when I tell you where the slides are you can read all about them.
But I do want to talk about one final thought from Dr. Peter Levine. He says that resilience strength is the opposite of helplessness. Being resilient means that we don't see things from the perspective of things that happen to our organization — it's a matter of what can we do going forward. A culture of blame creates a culture of helplessness.
You can find these slides and other talks I've given on these topics and things connected around incident response and outages at speaking.mattstratton.com.
With that, thank you very much for having me be part of DevOps Days Copenhagen. I look forward to talking to all of you in the open spaces, and thank you again.