BLAMELESS POSTMORTEMS HOW TO ACTUALLY DO THEM Matty Stratton DevOps Advocate & Thought Validator, PagerDuty @mattstratton
Slide 1

Slide 2
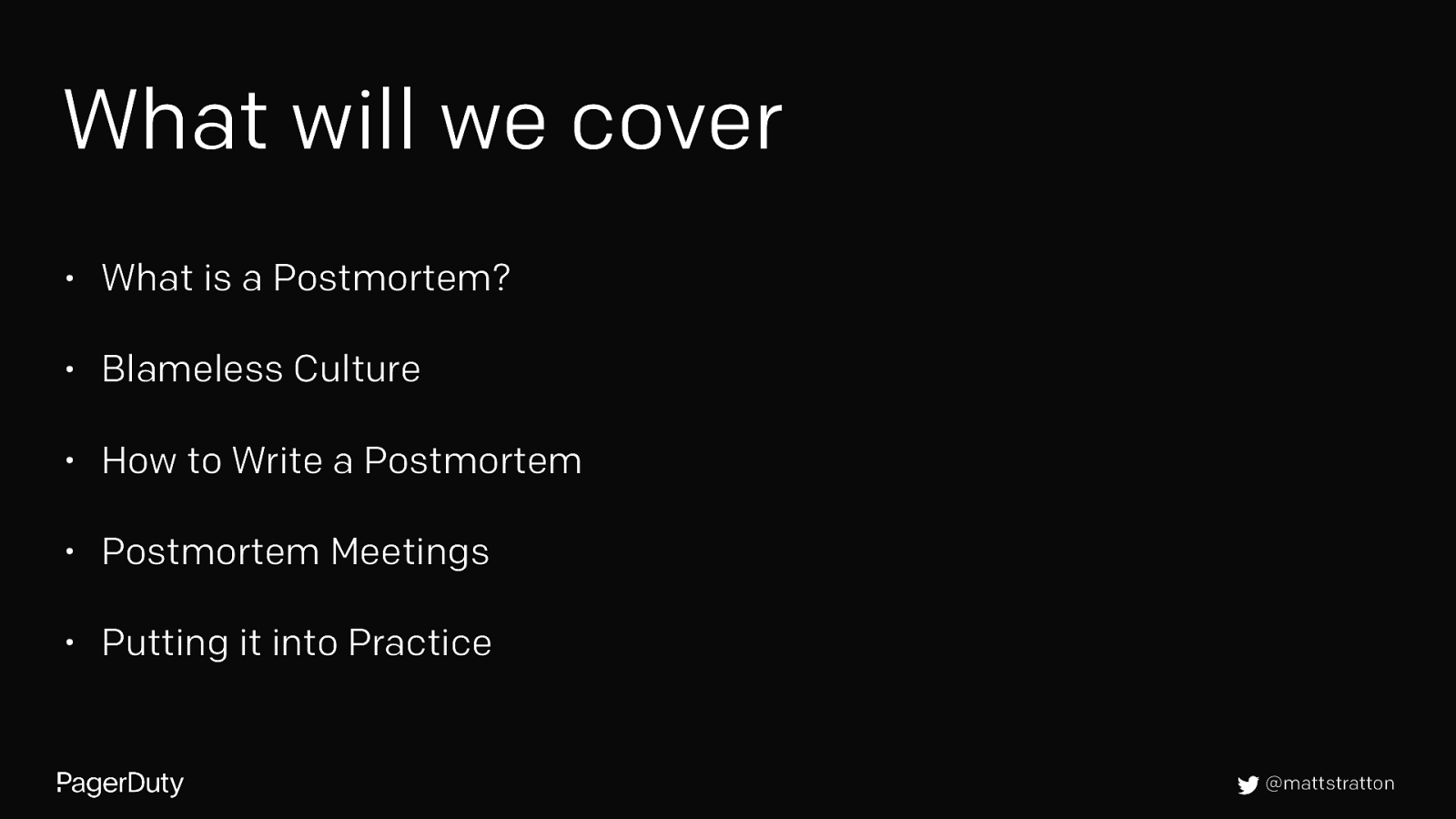
What will we cover • What is a Postmortem? • Blameless Culture • How to Write a Postmortem • Postmortem Meetings • Putting it into Practice @mattstratton
Slide 3

What is a postmortem? @mattstratton
Slide 4

What went wrong, and how do we learn from it? @mattstratton
Slide 5

Organizations may refer to the postmortem process in slightly different ways After-Action Review Post-Incident Review Learning Review Incident Review Incident Report Root Cause Analysis (or RCA) @mattstratton
Slide 6

Why do postmortems? @mattstratton
Slide 7

KEY TAKEAWAY The postmortem process drives focus, instills a culture of learning, and identifies opportunities for improvement that otherwise would be lost. @mattstratton
Slide 8

When to do a postmortem @mattstratton
Slide 9

Do a postmortem after every major incident @mattstratton
Slide 10

Postmortems are done shortly after the incident is resolved, while the context is still fresh for all responders. @mattstratton
Slide 11

Who is responsible for the postmortem? @mattstratton
Slide 12

Designate a single owner @mattstratton
Slide 13

Ownership Criteria • Took a leadership role during the incident • Performed a task that led to stabilizing the service • Was the primary on-call responder for the most heavily affected service • Manually triggered the incident to initiate incident response @mattstratton
Slide 14

Dedicated investigators @mattstratton
Slide 15

Postmortems are not a punishment @mattstratton
Slide 16

Blameless @mattstratton
Slide 17

KEY TAKEAWAY The impulse to blame and punish has the unintended effect of disincentivizing the knowledge sharing required to learn from incidents @mattstratton
Slide 18

KEY TAKEAWAY The goal of the postmortem is to understand what systemic factors led to the incident and identify actions that can improve the resiliency of the affected system @mattstratton
Slide 19

Why blamelessness is hard @mattstratton
Slide 20

J. Paul Reed Principal Consultant, Release Engineering Approaches Humans are hardwired through millions of years of evolutionary neurobiology and thousands of years of social conditioning to use the technique of blaming as a way to give voice to painful and uncomfortable feelings, in order to effectively disperse them from our psyches @mattstratton
Slide 21

By being aware of our biases, we will be able to identify when they occur and work to move past them @mattstratton
Slide 22

Fundamental attribution error @mattstratton
Slide 23

Confirmation bias @mattstratton
Slide 24

Hindsight bias @mattstratton
Slide 25

Negativity bias @mattstratton
Slide 26
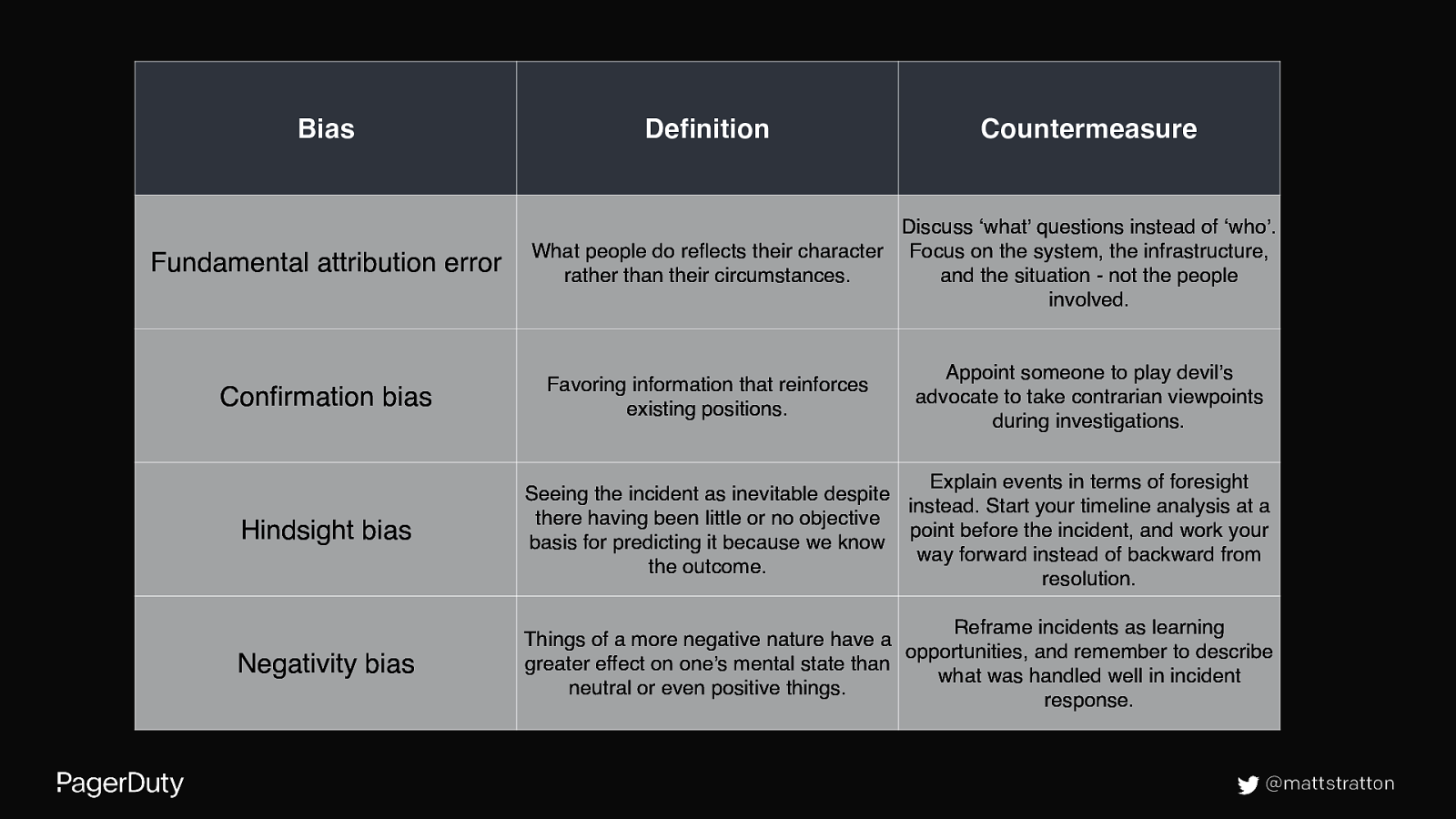
Bias Fundamental attribution error Confirmation bias Definition Countermeasure Discuss ‘what’ questions instead of ‘who’. What people do reflects their character Focus on the system, the infrastructure, rather than their circumstances. and the situation - not the people involved. Favoring information that reinforces existing positions. Appoint someone to play devil’s advocate to take contrarian viewpoints during investigations. Hindsight bias Explain events in terms of foresight Seeing the incident as inevitable despite instead. Start your timeline analysis at a there having been little or no objective point before the incident, and work your basis for predicting it because we know way forward instead of backward from the outcome. resolution. Negativity bias Reframe incidents as learning Things of a more negative nature have a opportunities, and remember to describe greater effect on one’s mental state than what was handled well in incident neutral or even positive things. response. @mattstratton
Slide 27

How to avoid blame @mattstratton
Slide 28

KEY TAKEAWAY Ask “what” and “how” questions rather than “who” or “why” @mattstratton
Slide 29

Consider multiple and diverse perspectives @mattstratton
Slide 30

Ask yourself why a reasonable, rational, and decent person may have taken a particular action @mattstratton
Slide 31

Abstract to an inspecific responder @mattstratton
Slide 32

Contrast what you did not intend with what you do intend @mattstratton
Slide 33

How to introduce postmortems @mattstratton
Slide 34

Sell the business value of blamelessness @mattstratton
Slide 35

Acknowledge that practicing blamelessness is difficult for everyone @mattstratton
Slide 36

Get buy-in from individual contributors too @mattstratton
Slide 37

Psychological safety @mattstratton
Slide 38

Amy Edmondson Professor, Harvard Business School [Psychological safety is] a sense of confidence that the team will not embarrass, reject, or punish someone for speaking up. @mattstratton
Slide 39

Conversational turn-taking @mattstratton
Slide 40

High social sensitivity or empathy @mattstratton
Slide 41

Start small @mattstratton
Slide 42

Information sharing @mattstratton
Slide 43

Being transparent about system failure reinforces a culture of blamelessness @mattstratton
Slide 44

Create a community of experienced postmortem writers to review postmortem drafts and spread good practices @mattstratton
Slide 45

Schedule postmortem meetings on a shared calendar @mattstratton
Slide 46

Email completed postmortems to all teams involved in incident response @mattstratton
Slide 47

Accountability @mattstratton
Slide 48

Set a policy for postmortem action items @mattstratton
Slide 49

Clarify ownership of postmortem action items @mattstratton
Slide 50

Engage the leaders that prioritize work @mattstratton
Slide 51

Open tickets for postmortem action items in your work management ticketing system @mattstratton
Slide 52

Actually doing it @mattstratton
Slide 53
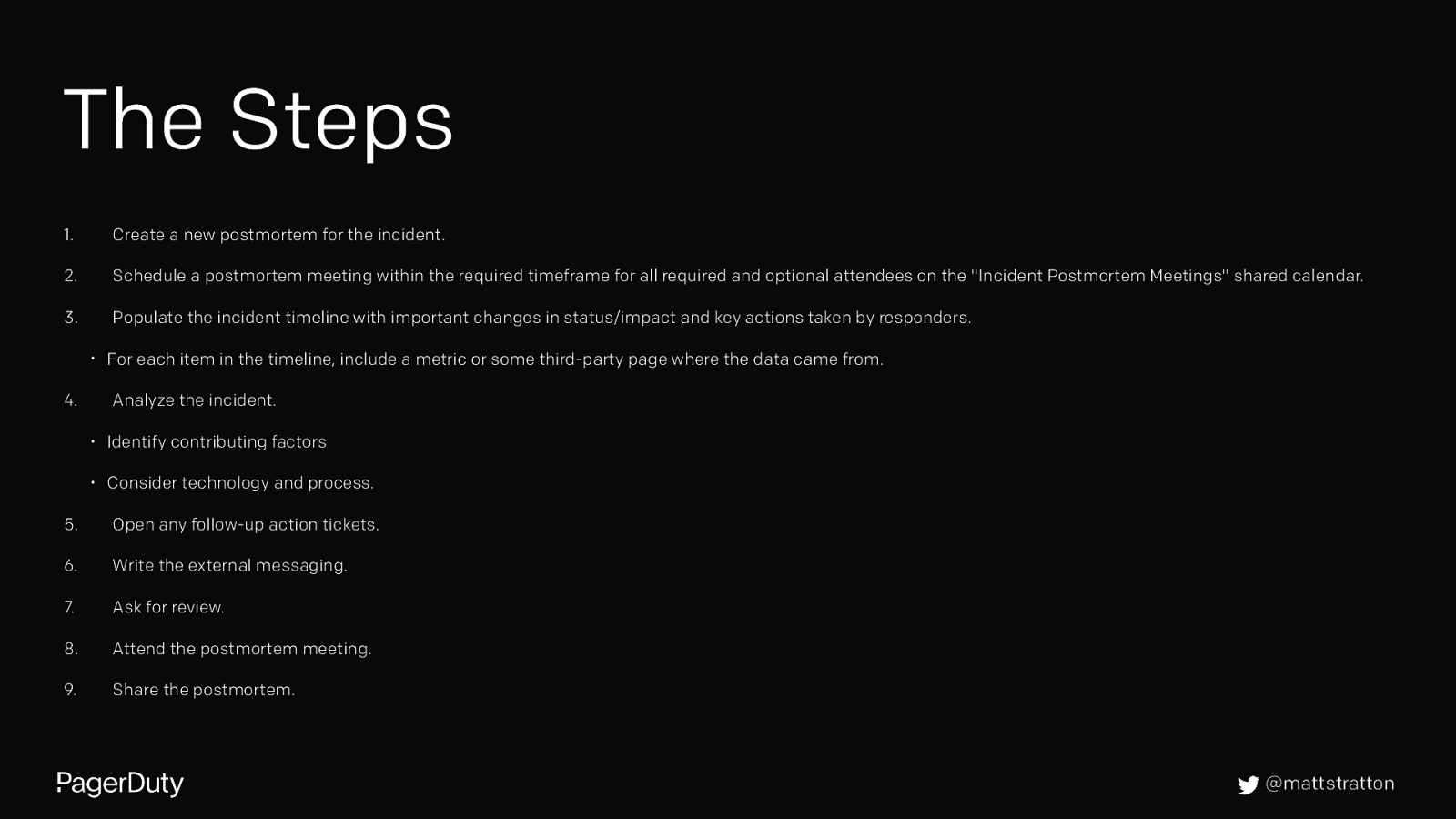
The Steps 1. Create a new postmortem for the incident. 2. Schedule a postmortem meeting within the required timeframe for all required and optional attendees on the “Incident Postmortem Meetings” shared calendar. 3. Populate the incident timeline with important changes in status/impact and key actions taken by responders. • 4. For each item in the timeline, include a metric or some third-party page where the data came from. Analyze the incident. • Identify contributing factors • Consider technology and process. 5. Open any follow-up action tickets. 6. Write the external messaging. 7. Ask for review. 8. Attend the postmortem meeting. 9. Share the postmortem. @mattstratton
Slide 54

Owner responsibilities • Scheduling the postmortem meeting on the shared calendar and inviting the relevant people (this should be scheduled within 3 business days for a Sev-1 and 5 business days for a Sev-2). • Investigating the incident, pulling in whomever you need from other teams to assist in the investigation. • Ensuring the page is updated with all of the necessary content. Use your organization’s template for what should be included. • Creating follow-up tickets. (You are only responsible for creating the tickets, not following them up to resolution). • Reviewing the postmortem content with appropriate parties before the meeting. Running through the topics at the postmortem meeting (the Incident Commander will “run” the meeting and keep the discussion on track, but you will likely be doing most of the talking). • Communicating the results of the postmortem internally. @mattstratton
Slide 55

Administration @mattstratton
Slide 56

Who should attend? • Service owners involved or impacted in the incident. • Key engineer(s)/responders involved in the incident. • Engineering manager for impacted systems. • Product manager for impacted systems. • Customer liaison (only for Sev-1 incidents). • Incident commander and/or a facilitator • Incident commander deputy, shadow, scribe (if present). @mattstratton
Slide 57

Create a timeline @mattstratton
Slide 58

Timeline tips • Stick to the facts. • Include changes to incident status and impact. • Include key decisions and actions taken by responders. • Illustrate each point with a metric. @mattstratton
Slide 59

Document the impact @mattstratton
Slide 60

Analyze the incident @mattstratton
Slide 61

KEY TAKEAWAY There is no single root cause of major failure in complex systems, but a combination of contributing factors that together lead to failure @mattstratton
Slide 62

KEY TAKEAWAY An individual’s action should never be considered a root cause. @mattstratton
Slide 63

Dr. Richard Cook Department of Integrated Systems Engineering at the Ohio State University All practitioner actions are actually gambles, that is, acts that take place in the face of uncertain outcomes. @mattstratton
Slide 64

Check data @mattstratton
Slide 65

Helpful questions • Is it an isolated incident or part of a trend? • Was this a specific bug, a failure in a class of problem we anticipated, or did it uncover a class of issue we did not architecturally anticipate? • Was there work the team chose not to do in the past that contributed to this incident? • Research if there were any similar or related incidents in the past. Does this incident demonstrate a larger trend in your system? • Will this class of issue get worse/more likely as you continue to grow and scale the use of the service? @mattstratton
Slide 66

Follow-up actions @mattstratton
Slide 67
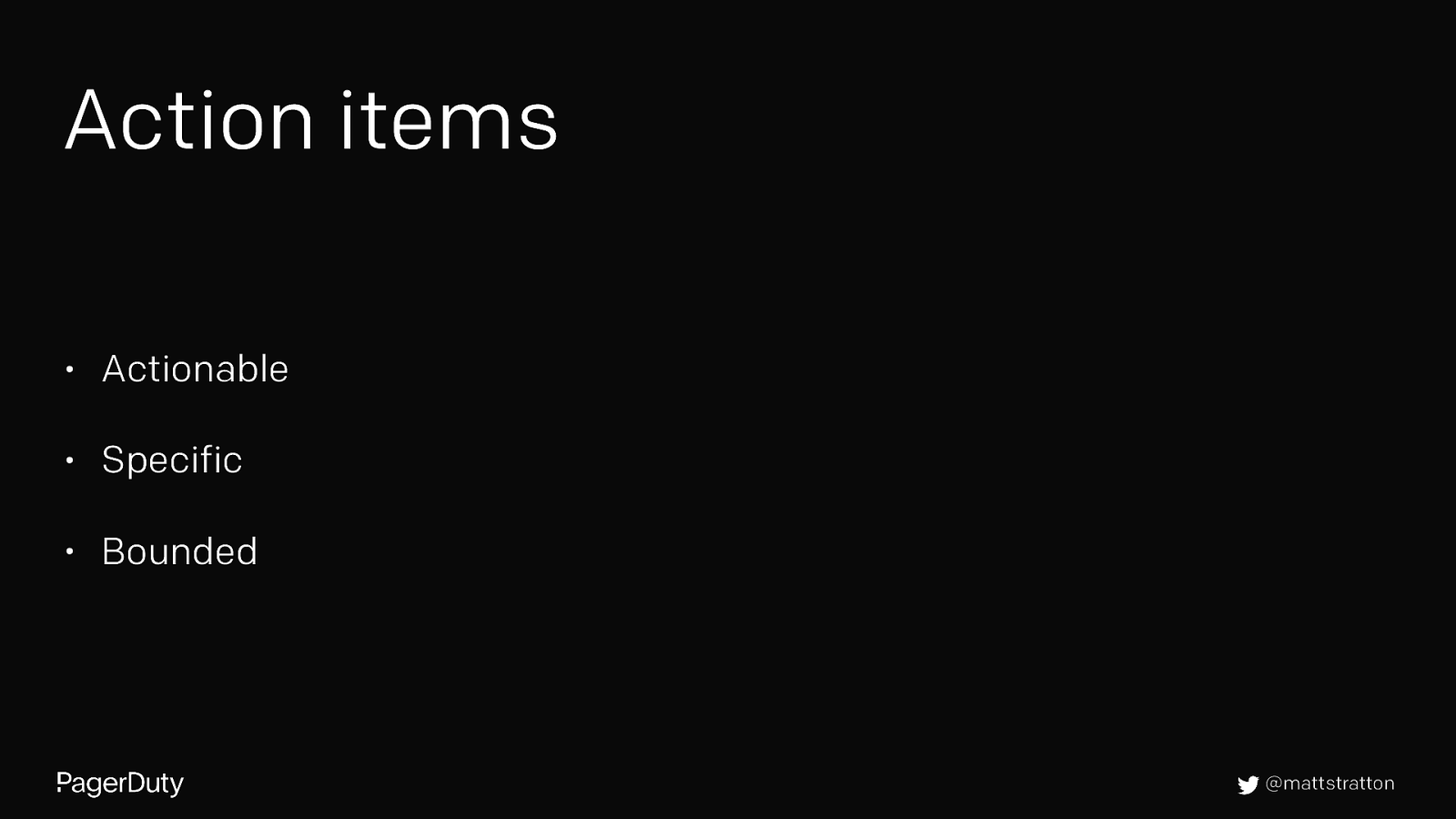
Action items • Actionable • Specific • Bounded @mattstratton
Slide 68
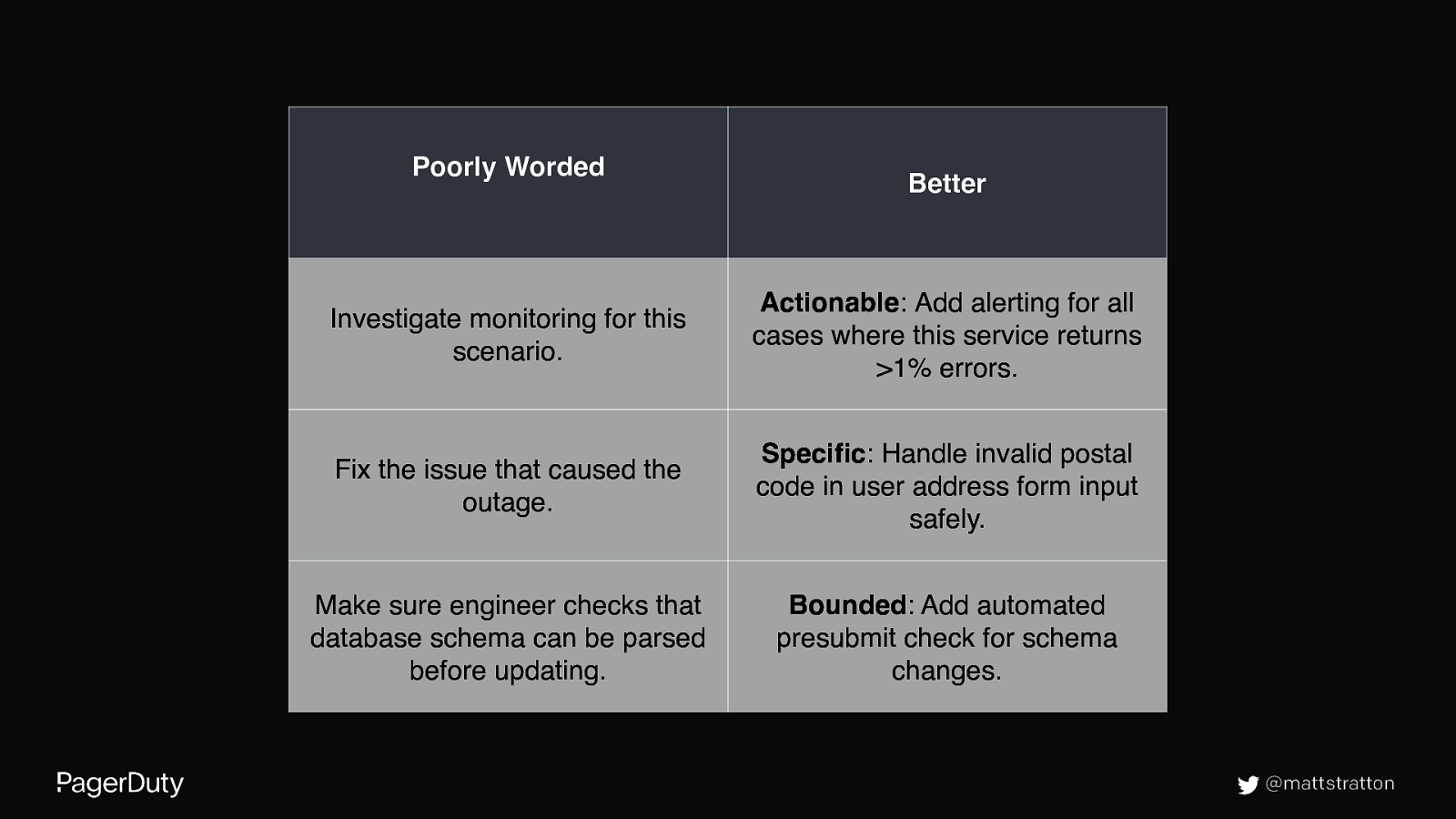
Poorly Worded Better Investigate monitoring for this scenario. Actionable: Add alerting for all cases where this service returns >1% errors. Fix the issue that caused the outage. Specific: Handle invalid postal code in user address form input safely. Make sure engineer checks that database schema can be parsed before updating. Bounded: Add automated presubmit check for schema changes. @mattstratton
Slide 69

Don’t create too many tickets @mattstratton
Slide 70

The person who creates the ticket is not responsible for completing it @mattstratton
Slide 71

Write external messaging @mattstratton
Slide 72

External messaging components • Summary: Two to three sentences that summarize the duration of the incident and the observable customer impact. • What Happened: Summary of contributing factors. Summary of customer-facing impact during the incident. Summary of mitigation efforts during the incident. • What Are We Doing About This: Summary of action items. @mattstratton
Slide 73

Postmortem Review @mattstratton
Slide 74

Do • • Make sure the timeline is an accurate representation of events. Define any technical lingo/acronyms you use that newcomers may not understand. • Separate what happened from how to fix it. • Write follow-up tasks that are actionable, specific, and bounded in scope. • Discuss how the incident fits into our understanding of the health and resiliency of the services affected. @mattstratton
Slide 75
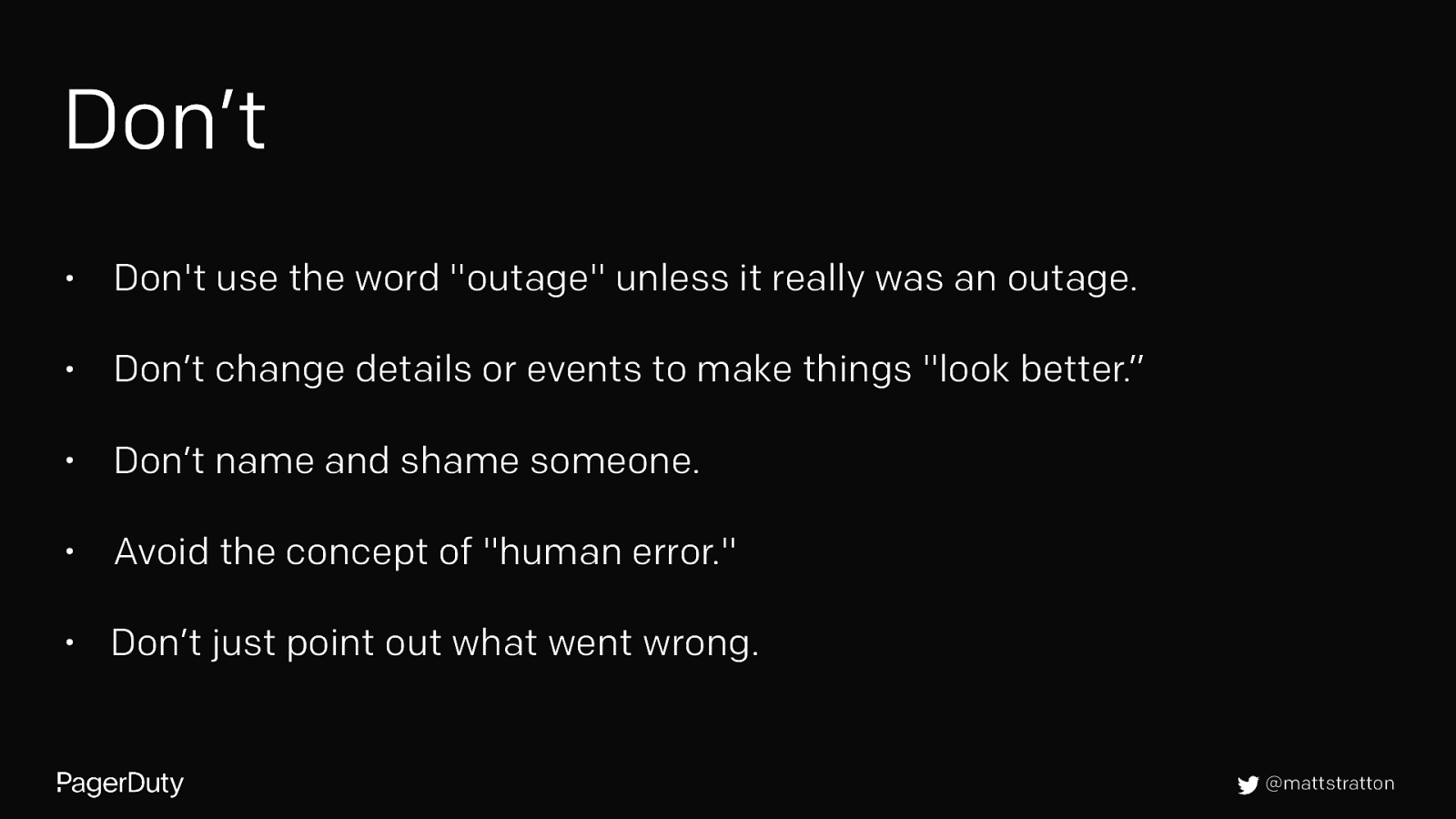
Don’t • Don’t use the word “outage” unless it really was an outage. • Don’t change details or events to make things “look better.” • Don’t name and shame someone. • Avoid the concept of “human error.” • Don’t just point out what went wrong. @mattstratton
Slide 76

The postmortem meeting @mattstratton
Slide 77

Send the postmortem document in advance @mattstratton
Slide 78

KEY TAKEAWAY An essential outcome of the postmortem meeting is buy-in for the action plan @mattstratton
Slide 79
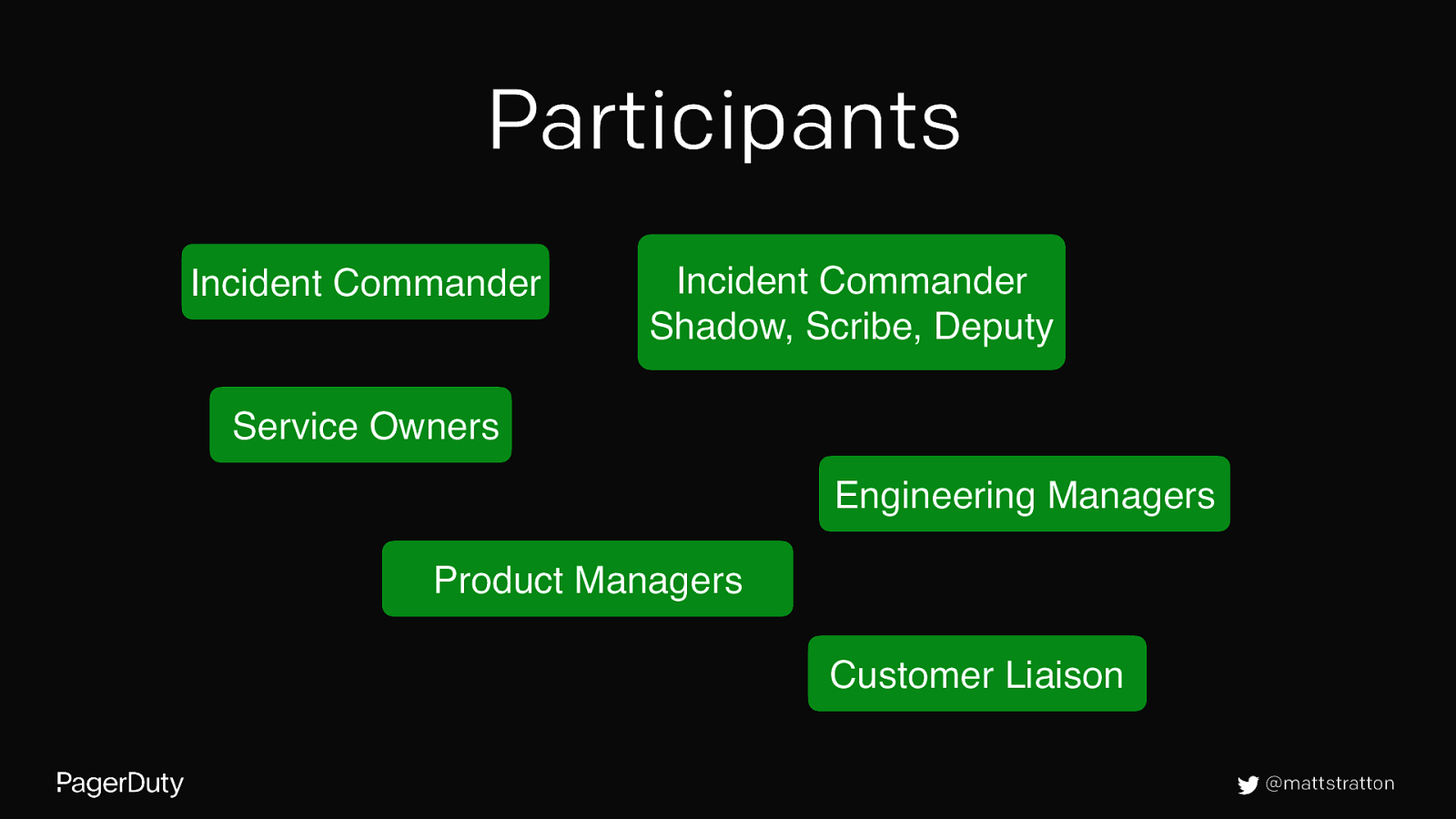
Participants Incident Commander Incident Commander Shadow, Scribe, Deputy Service Owners Engineering Managers Product Managers Customer Liaison @mattstratton
Slide 80

Facilitation @mattstratton
Slide 81

Facilitator’s Role • Encourage people to speak up, and make sure that everyone is heard. • Clarify insights and challenge the team with questions. • Help the team to see different angles and different options. • Keep everyone on time and on track. Cut off tangents and stop people from dominating the entire meeting. @mattstratton
Slide 82

More on facilitation • The facilitator does not make decisions. • The facilitator does not take sides. • Try to speak as little as possible. • Be a shadow that guides discussions, not a presenter who takes over the meeting. @mattstratton
Slide 83

Who should facilitate? @mattstratton
Slide 84

Facilitator competencies • Reads non-verbal cues to assess how people are feeling in the room and sees who might have something to say. • Paraphrases what is said to clarify for self and others. • Asks open questions to stimulate deeper thinking. • Comfortable interrupting when discussion gets off track or someone dominates the discussion. • Redirects conversation to focus on goals. • Drives discussion to decision making and action items. @mattstratton
Slide 85

Facilitation tips @mattstratton
Slide 86

Housekeeping • Set ground rules at the beginning of the meeting. • Establish a safeword for when the conversation gets off track. • Share the agenda so the team is clear on what is on- and off-topic. • Use a timer to timebox. • Present the postmortem document from your laptop onto the TV so everyone can see. @mattstratton
Slide 87

Avoid blame @mattstratton
Slide 88

Keep on-topic @mattstratton
Slide 89

One person dominating? @mattstratton
Slide 90

Encourage contributions @mattstratton
Slide 91

Practice makes perfect @mattstratton
Slide 92
https://postmortems.pagerduty.com @mattstratton
Slide 93
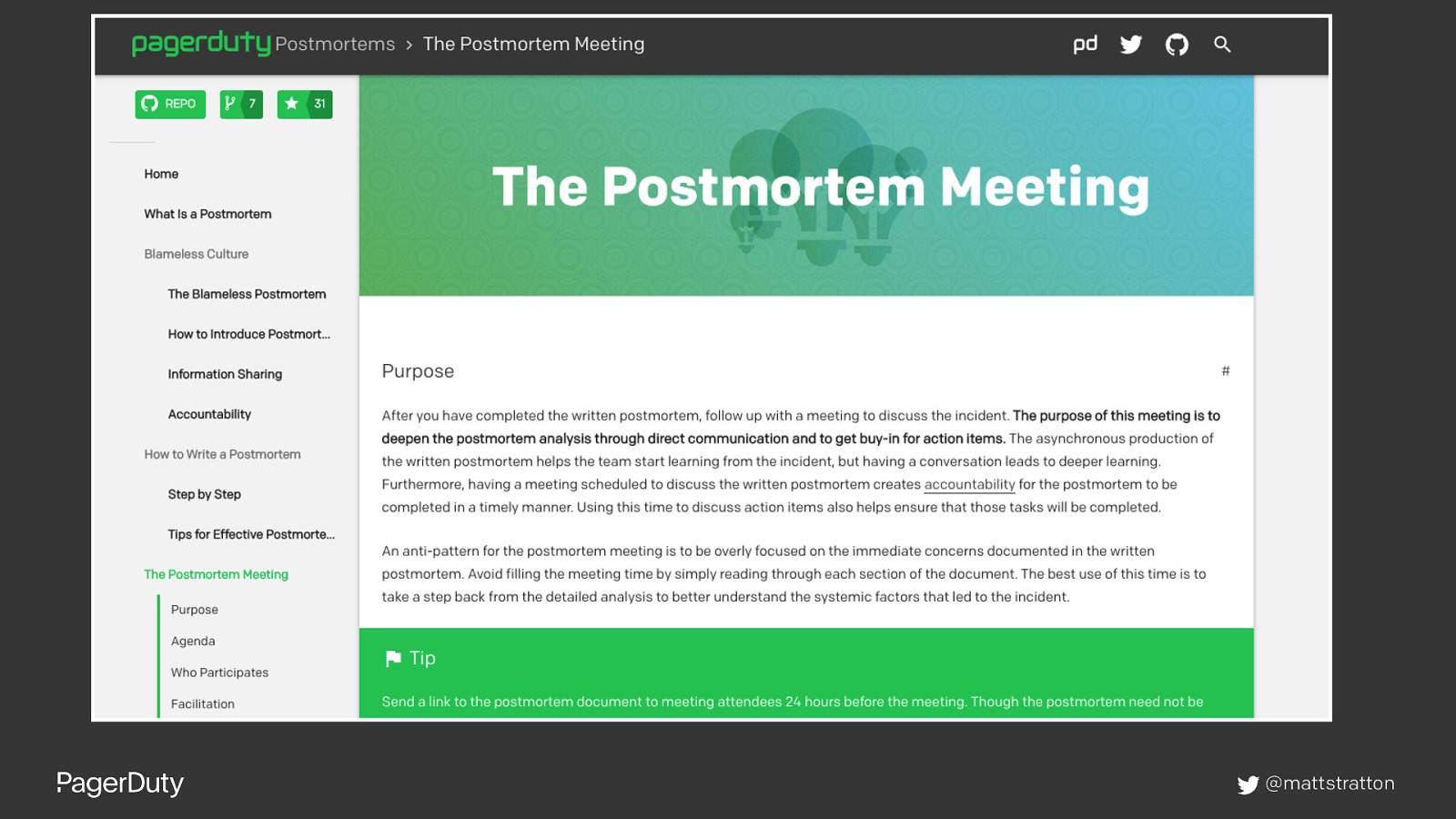
@mattstratton
Slide 94
pduty.me/dodpdx @mattstratton
Slide 95
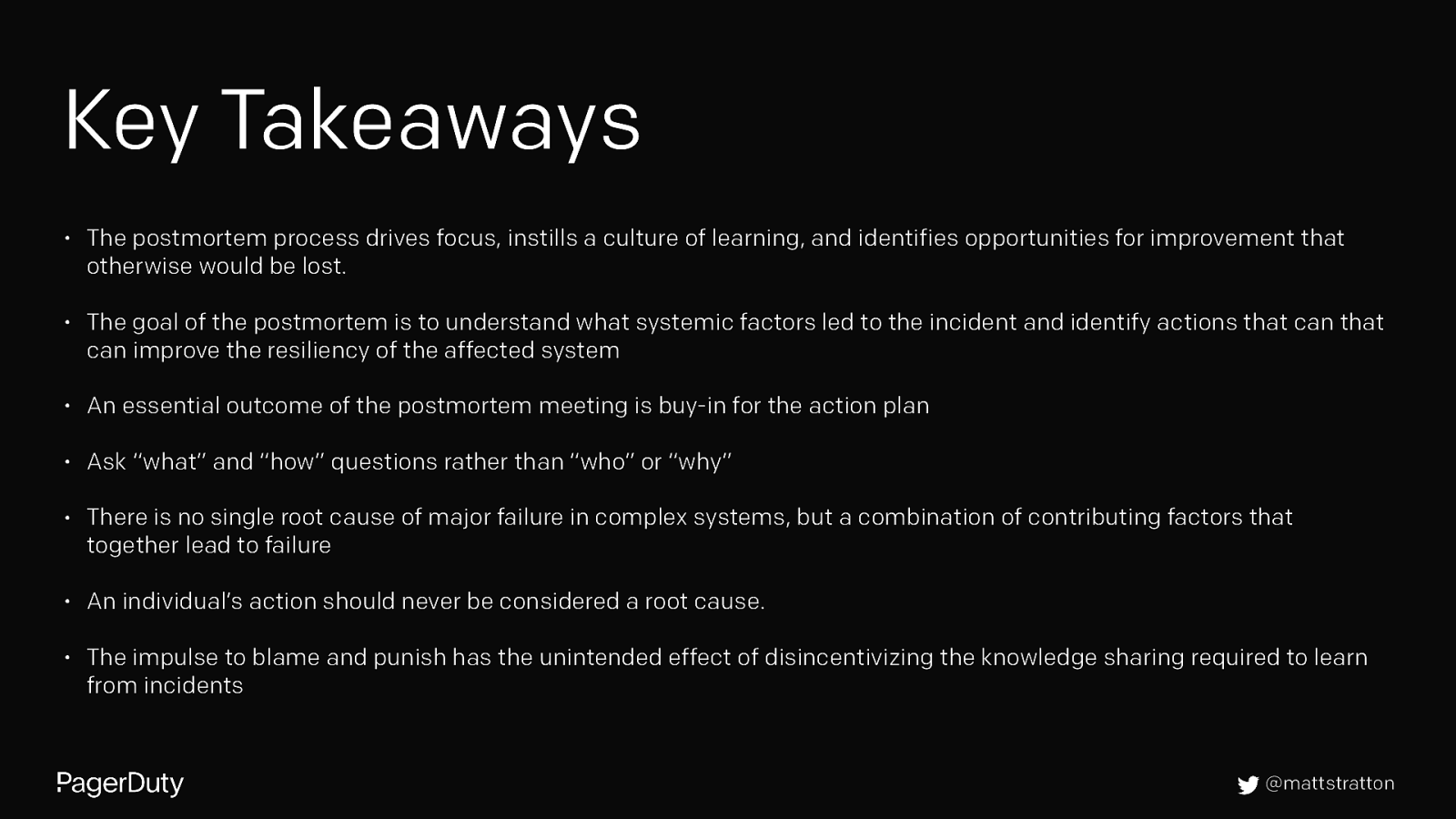
Key Takeaways • The postmortem process drives focus, instills a culture of learning, and identifies opportunities for improvement that otherwise would be lost. • The goal of the postmortem is to understand what systemic factors led to the incident and identify actions that can that can improve the resiliency of the affected system • An essential outcome of the postmortem meeting is buy-in for the action plan • Ask “what” and “how” questions rather than “who” or “why” • There is no single root cause of major failure in complex systems, but a combination of contributing factors that together lead to failure • An individual’s action should never be considered a root cause. • The impulse to blame and punish has the unintended effect of disincentivizing the knowledge sharing required to learn from incidents @mattstratton
Slide 96

Pagey says thank you @mattstratton