The talk
Incidents & Accidents
Delivered 3 times · 2018
















































In the course of #opslife, we run into production incidents. How do we best manage them to avoid 3am misery? Matt Stratton of PagerDuty joins us to talk about just that.
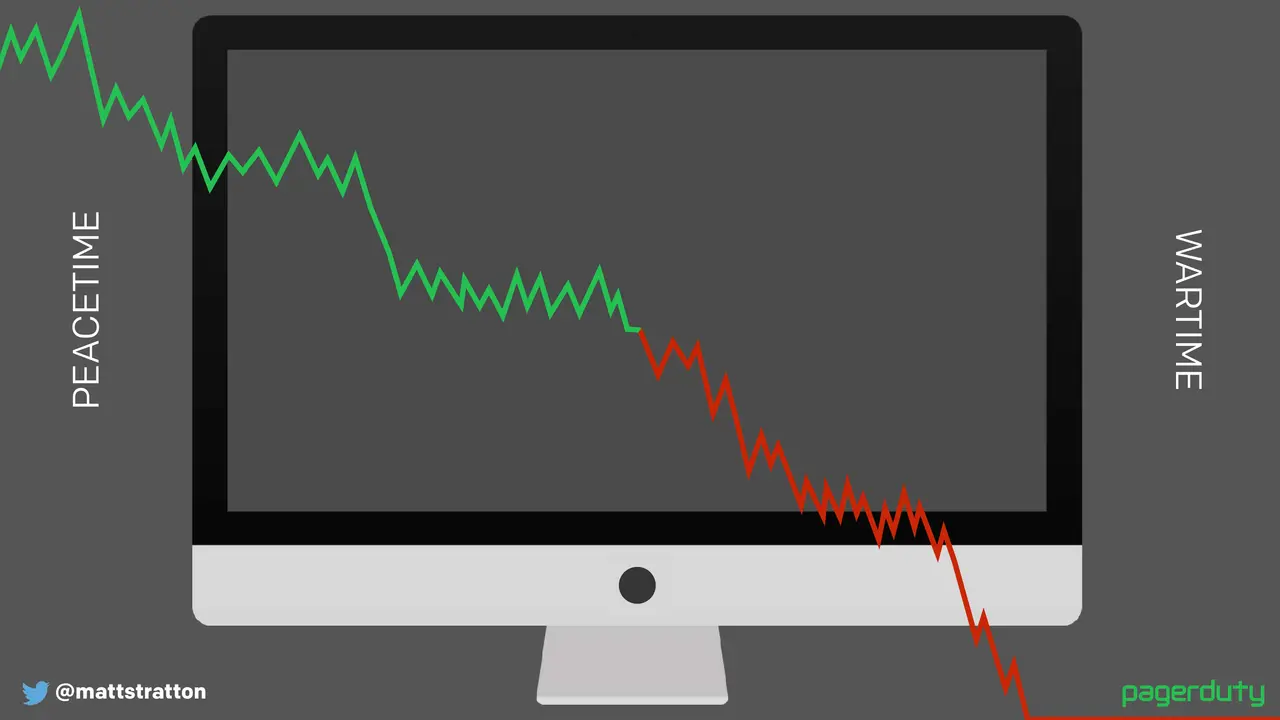
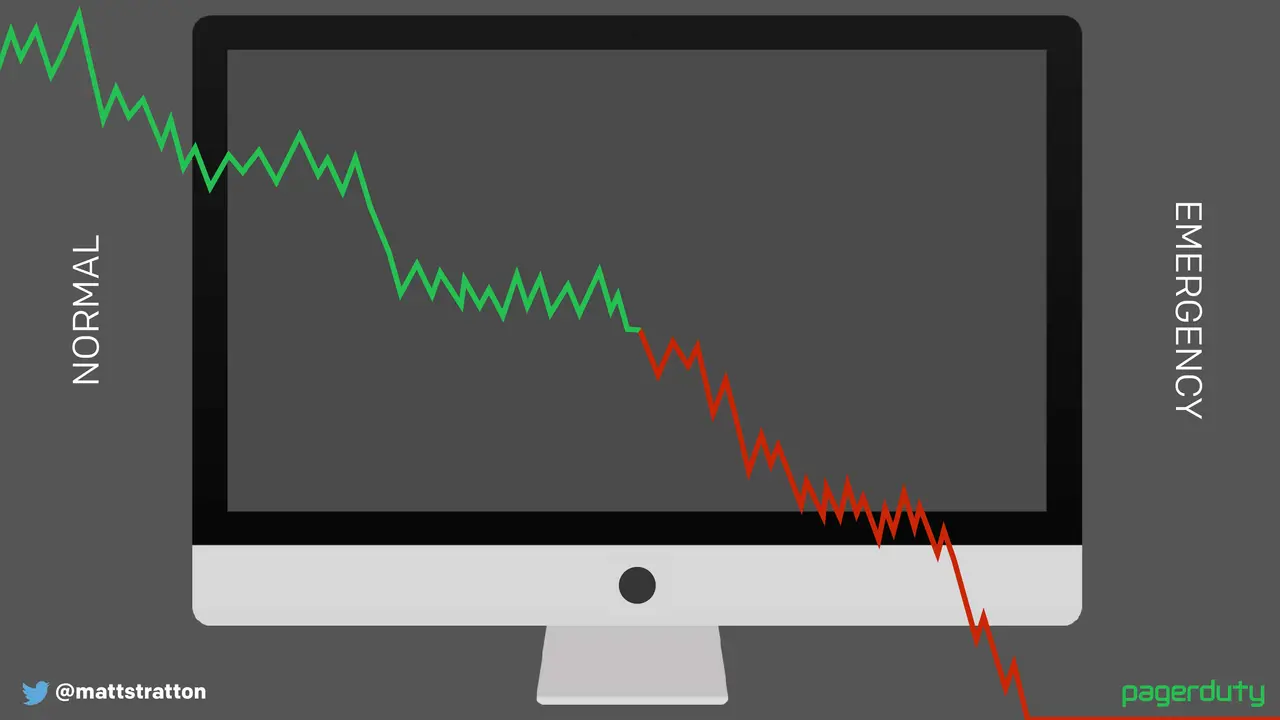
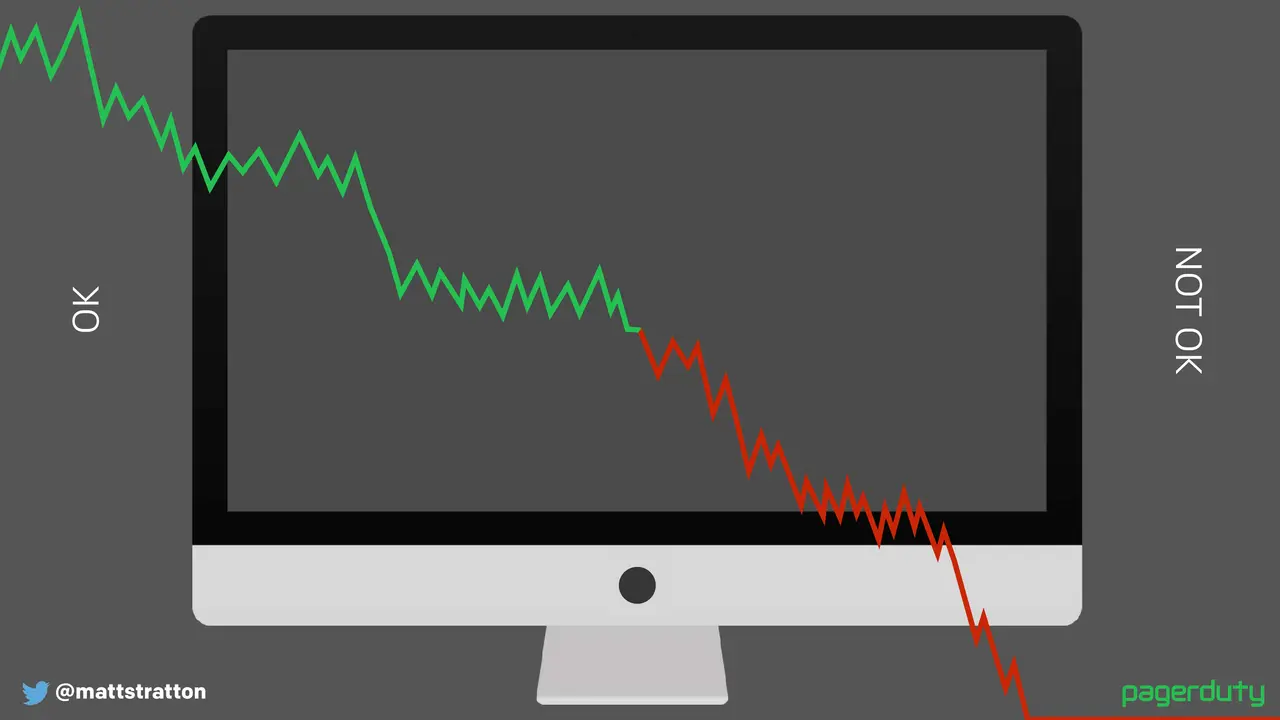
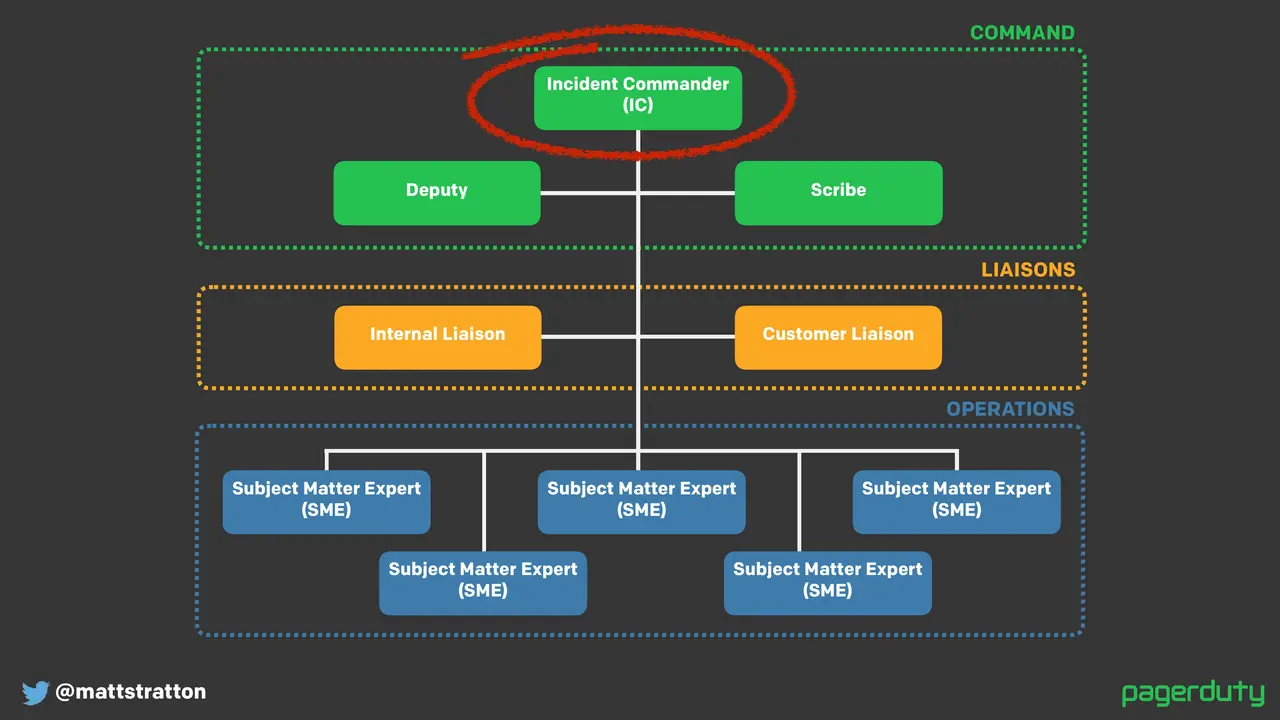
Major outages, incident calls, war rooms, whatever you want to label them, can be stressful and frustrating experiences. However, we aren't the only industry to have run into these problems. What can we learn from others on how to have a relatively stress free experience? How can we shorten the time that it takes to get back to a working state when things are broken?
This talk will provide some comparisons to responses in other industries, and then go through several patterns and processes any team or company can use to have a quick, visible, and easy time responding to problems.