The talk
The Four Agreements of Incident Response
Delivered 3 times · 2018–2019









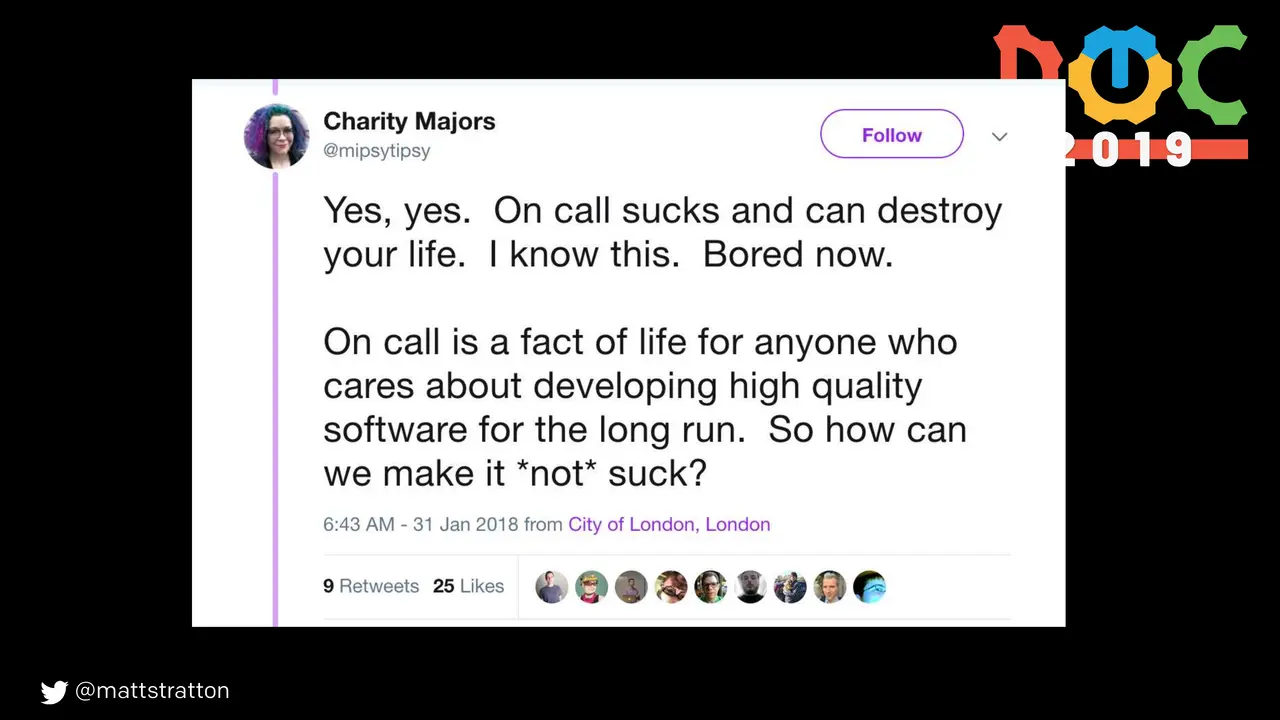


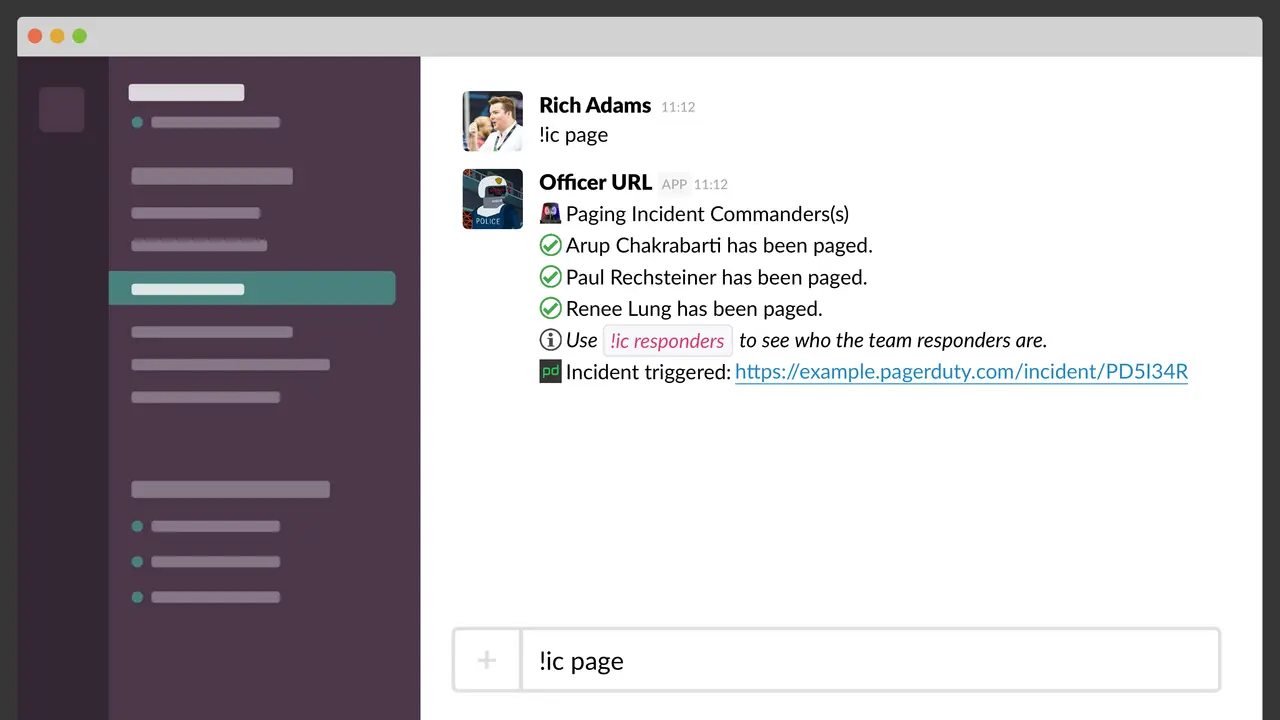







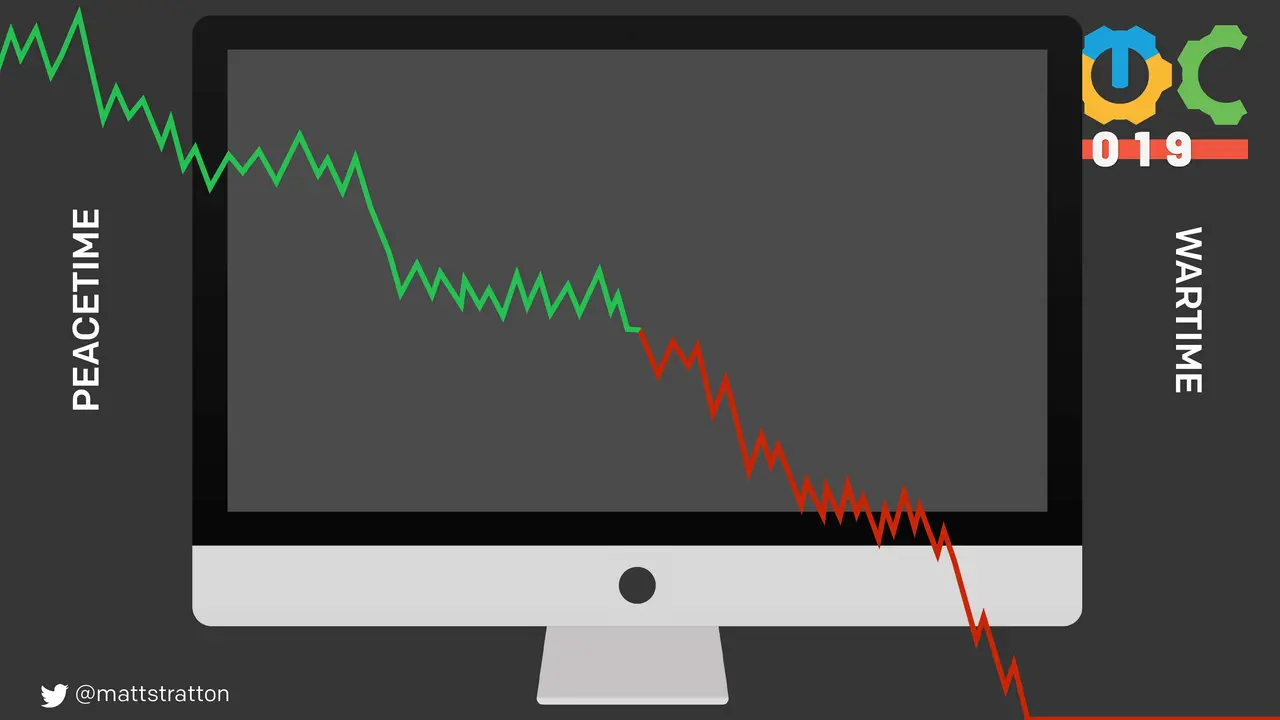
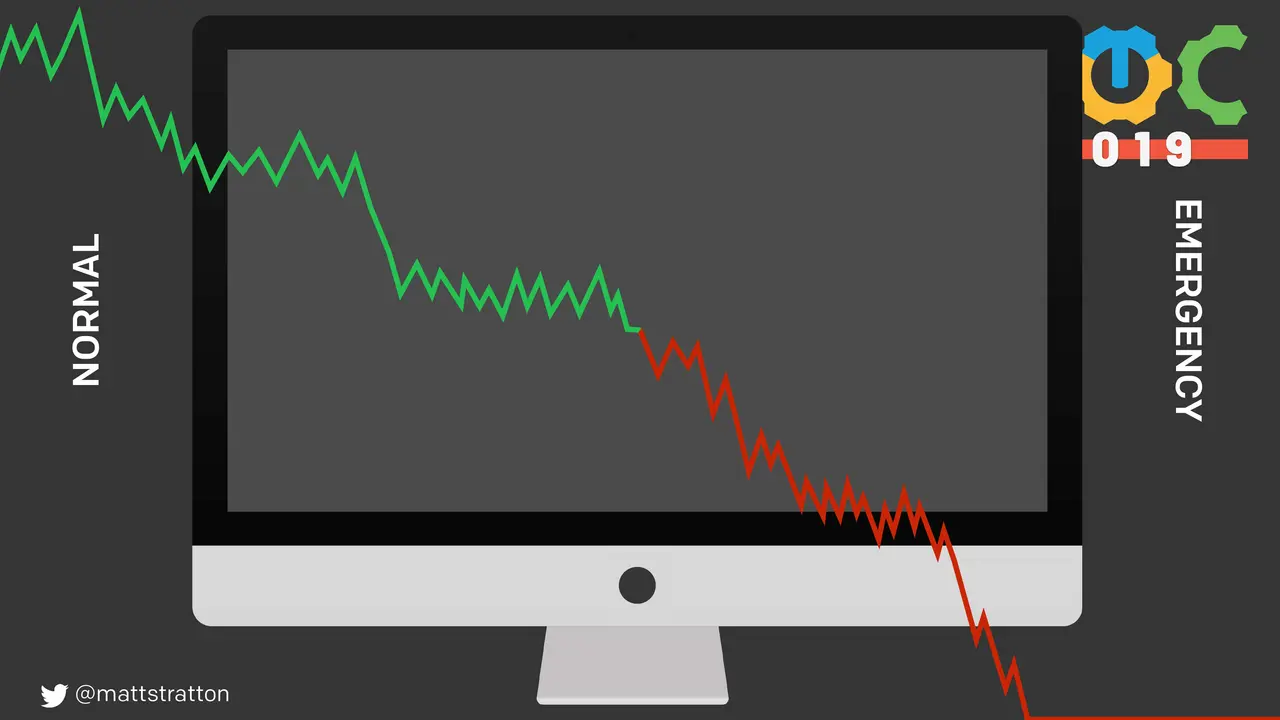




































Major outages, incident calls, war rooms, whatever you want to label them, can be stressful and frustrating experiences. In this talk, I will use the lessons of the book “The Four Agreements” by don Miguel Ruiz, to illustrate an easy-to-remember modality for effective and humane incident response.
Don Miguel Ruiz’s book, The Four Agreements, presents a code of personal conduct based on ancient Toltec wisdom to help remove self-limiting structures and beliefs.
Each of the Four Agreements can help us understand a more mature, effective, and humane approach to incident response in our organizations. In this talk, I will address how the Agreements can be expressed as a modality for Incident Response. Using the Agreements, it is easier to understand modern approaches to resolving incidents as effectively as possible, and even help reduce burnout as well!
Incident ResponseThe Human Side#PagerDuty