The talk
The Journey From DevOps to Cloud Engineering
Delivered 8 times · 2021–2022



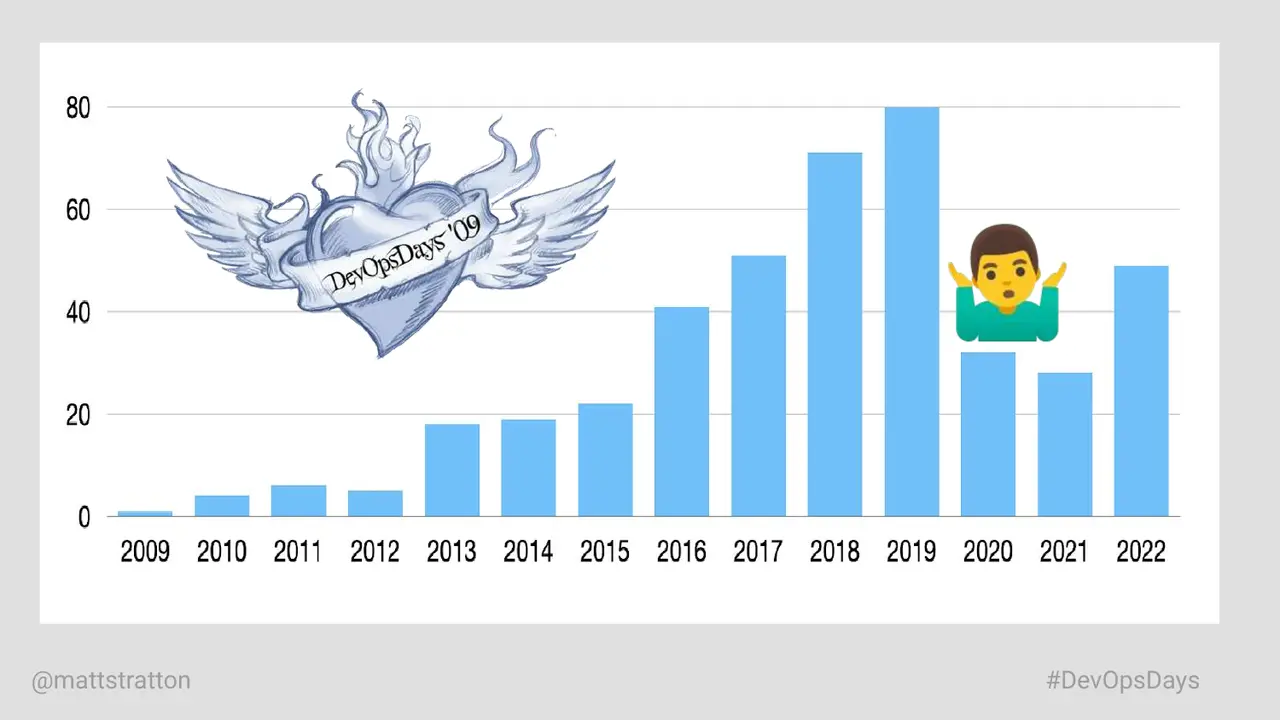








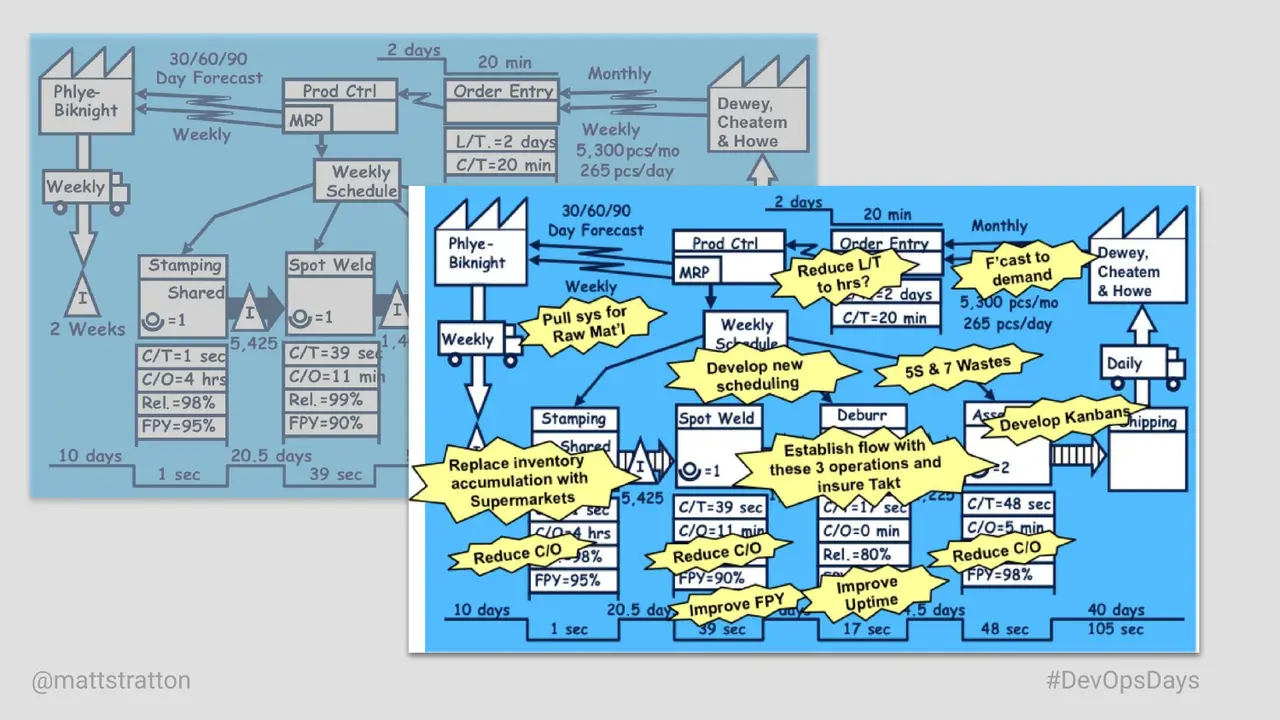


































We have been talking about devops for years. Along the way, we’ve added various syllables to the portmanteau “devops” to include all the practices and disciplines that are key to doing this effectively. What if DevOps, DevSecOps, and all the other variants have been about the same idea all along?
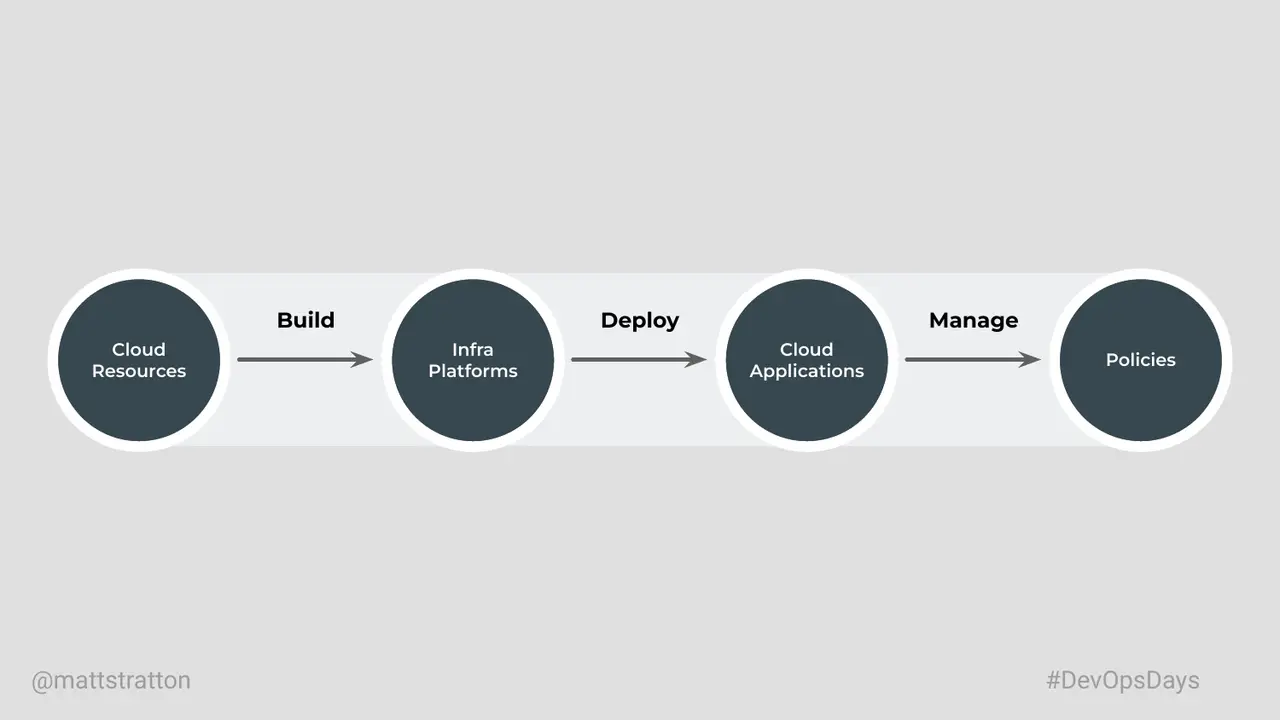
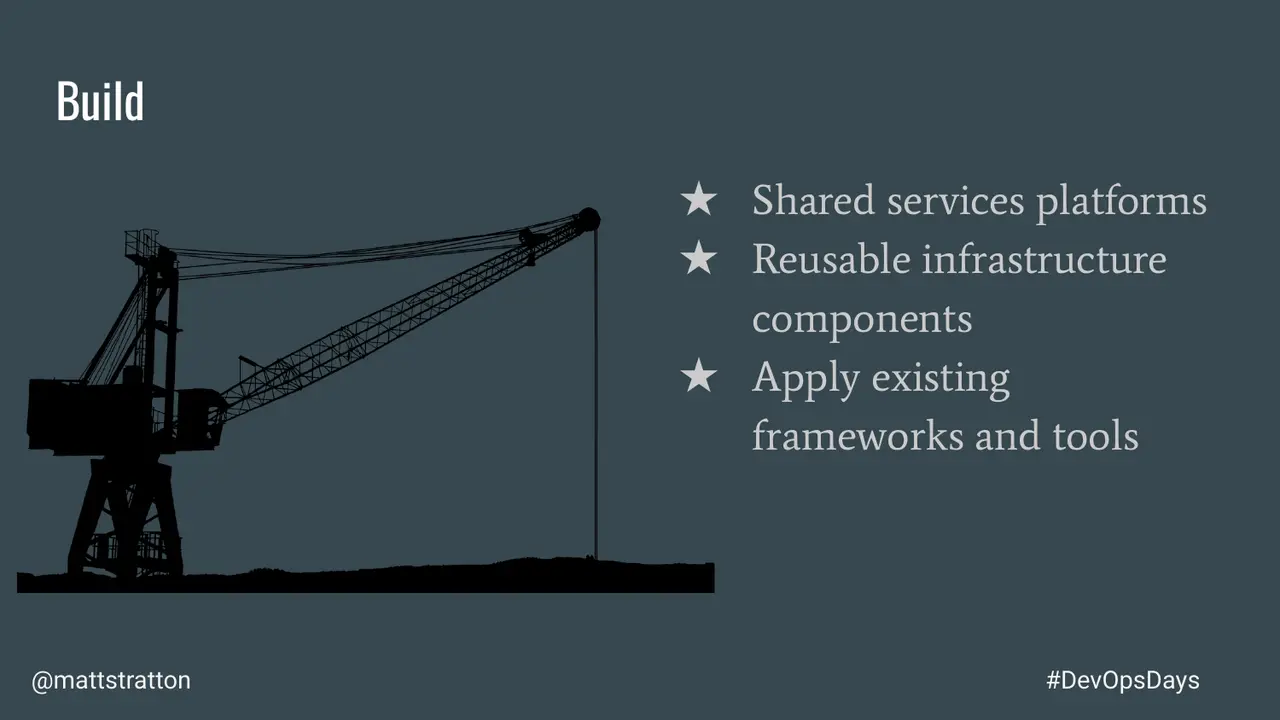
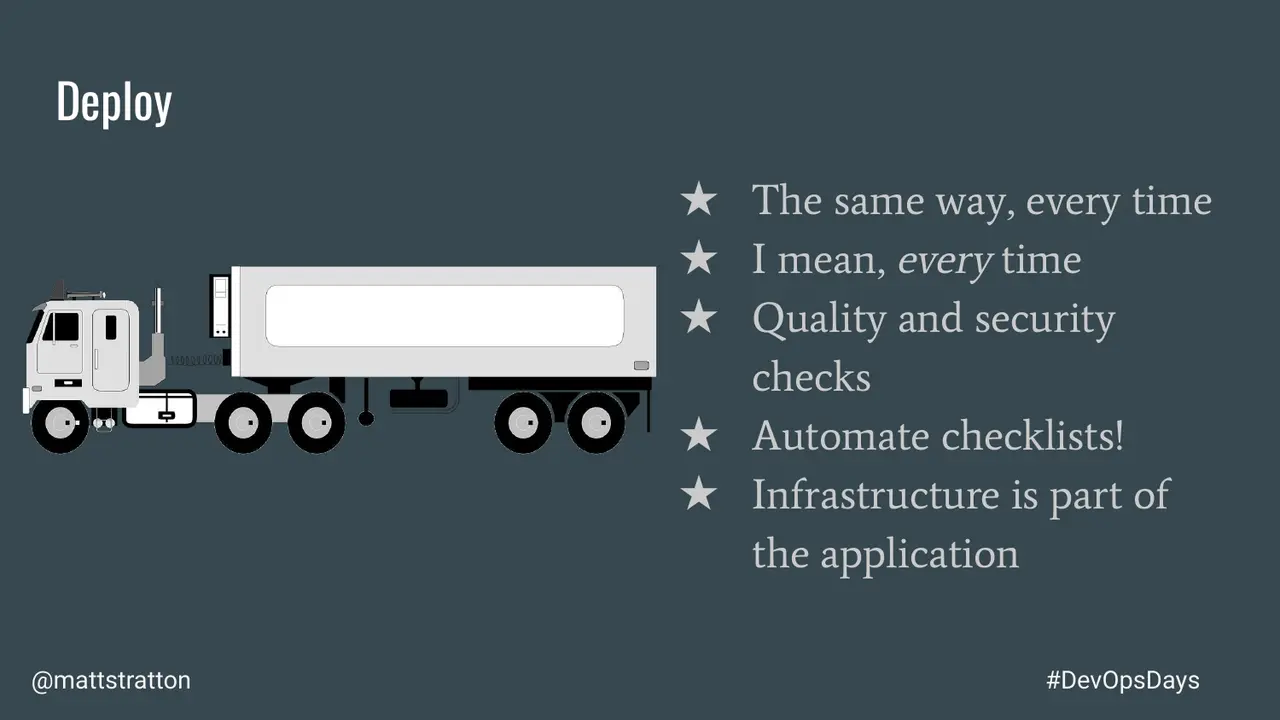
Cloud Engineering is an emergent way of expressing how we use and enhance software engineering practices in a cloud world. This goes beyond application design and architecture but includes how we build, deploy, and manage the services and applications that provide value to our users and customers.
In this talk I will step through the evolution of devops and how the practice of Cloud Engineering is a natural progression. I will take the traditional expression of CALMS (Culture, Automation, Lean, Measurement, and Sharing) and connect them to the build, deploy, and manage practices reflected in the Cloud Engineering discipline.
Cloud Engineering isn’t “the new DevOps”. It’s the evolution of everything we have been talking about for the last ten years (and more). Let’s learn how we can provide innovation, scale, reliability, security, and compliance by harnessing the practices across all of the associate disciplines. And maybe, along the way, “take DevOps back” to what it’s really been about all this time.
DevOpsCloud Native & Kubernetes#Kubernetes#Pulumi
Every delivery (8)
- DevOpsDays London 2022 Sep 2022 · London, UK video slides
- DevOpsDays LA 2022 Jul 2022 · Los Angeles, CA, USA slides
- DevOpsDays Denver 2022 Apr 2022 · Denver, CO, USA slides
- DevOpsDays Raleigh 2022 Apr 2022 · Raleigh, NC, USA video slides
- Automation + DevOps Summit 2021 Nov 2021 · Nashville, TN, USA
- Citrix Converge 2021 Oct 2021 · Virtual slides
- Serverless Days - Student Edition Aug 2021 · Virtual slides
- DevOpsDays Medellín 2021 Jul 2021 · Medellín, Medellin, Antioquia, Colombia video slides
Resources
- Velocity 09 - “10+ Deploys Per Day: Dev and Ops Cooperation at Flickr”
- A Practical Approach to Large-Scale Agile Development: How HP Transformed LaserJet FutureSmart Firmware
- Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation
- DevOpsDays Ghent 2009
- Value Stream Thinking
- DevOps Cafe Ep. 33 - Guest: Jez Humble
- The Deployment Production Line
- WTF Is Cloud Engineering?
- DevOps Party Games
- CNCFaceOff
- 10+ Deploys Per Day at Flickr (Velocity)
- Practical Approach to Large-Scale Agile Development, A: How HP Transformed LaserJet FutureSmart Firmware
- Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation